
1. 爬虫数据提取——方法总结
我们获取了想要的html页面之后,接下来的问题就是如何将我们需要的数据给提取下来,一般来说有三种方式:分别是Xpath语法、正则表达式和bs4库。

2. 爬虫数据提取——Xpath环境配置
Xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。简单来说,我们的数据是超文本数据,想要获取超文本数据里面的内容,就要按照一定规则来进行数据的获取,这种规则就叫做Xpath语法。
XPath 用于在 HTML 文档中通过元素HTML标签和属性HTML标签的属性进行数据的定位。

所有的HTML标签都有很强的层级关系,正是基于这种层级关系,Xpath语法能够选择出我们想要的数据
Xpath环境配置安装
XPath Helper Google浏览器安装链接
https://chromewebstore.google.com/detail/xpath-helper/nmjjcokoigamfoklbjmhpmjajmcjbjld?hl=zh
3. Xpath语法
3.1 节点选取
| 表达式 | 描述 | 用法 | 说明 |
|---|---|---|---|
| nodename | 选取此节点的所有子节点 | div | 选取 div 下的所有标签 |
| // | 从全局节点中选择节点,任意位置均可 | //div | 选取整个 HTML 页面的所有 div 标签 |
| / | 选取某个节点下的节点 | //head/title | 选取 head 标签下的 title 标签 |
| @ | 选取带某个属性的节点 | //div[@id] | 选择带有 id 属性的 div 标签 |
| . | 当前节点下 | ./span | 选择当前节点下的 span 标签【代码中威力强大】 |
//表示全局搜索,//div即表示全局搜索所有的div标签

/表示标签下的局部搜索,//head/meta即表示head标签下所有meta标签

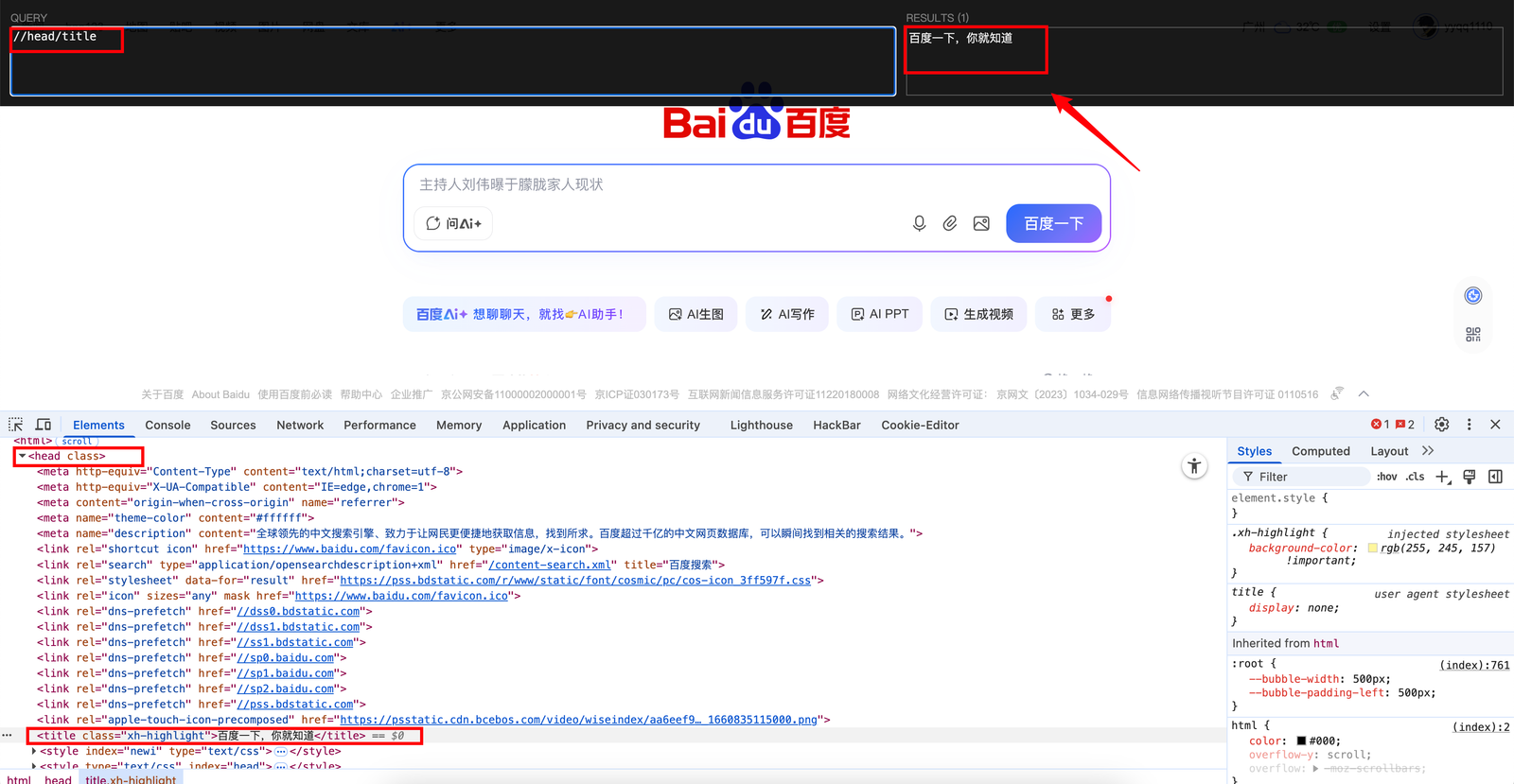
观察html页面,将head下的“百度一下,你就知道”提取出来。
//head/title
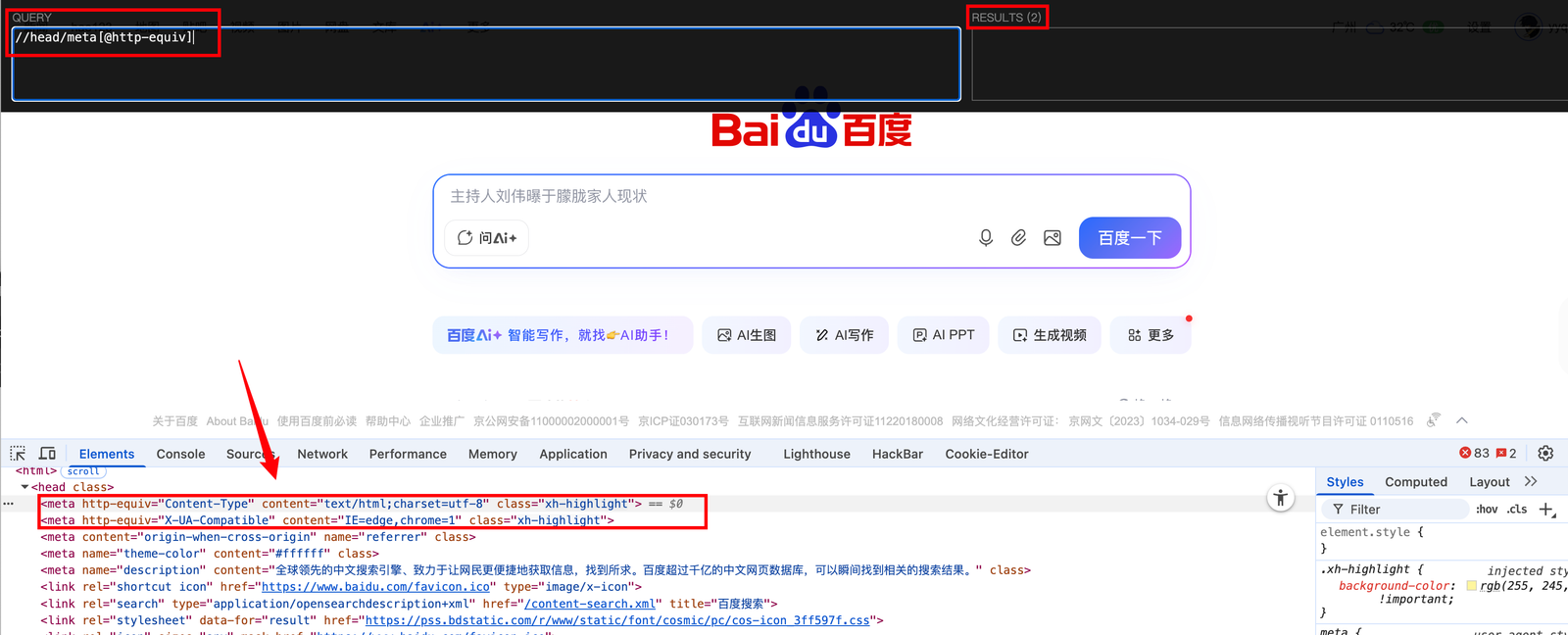
用[ ]括号内添加@,将标签属性填入进去,将含有该标签属性的部分提取出来。
//head/meta[@http-equiv],将head下的meta标签下的所有包含http-equiv属性的内容提取出来。
实例: 将百度页面左上方的这些信息通过Xpath提取出来?
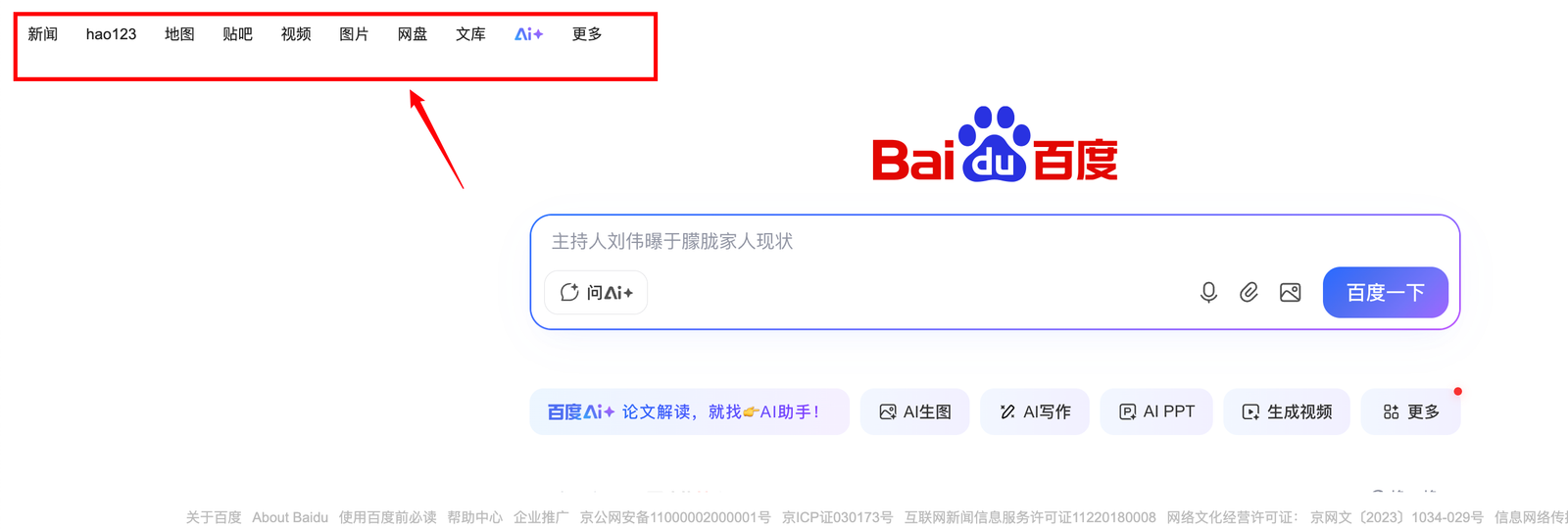
//div/div[@id="s-top-left"]/a|//div/div[@id="s-top-left"]/div/a

3.2 谓语
| 表达式 | 用法说明 |
|---|---|
//head/meta[1] //head/meta[k] |
选择所有head下的第一个meta标签 选择所有head下的第k个meta标签 |
//head/meta[last()] |
选择所有head下的最后一个meta标签 |
//head/meta[position()<3] |
选择所有head下的前两个meta标签 |
//div[@id] |
选择带有id属性的div标签 |
//div[@id='u1'] |
选择所有拥有id=u1的div标签 |
3.3 通配符
| 通配符 | 描述 | 示例 | 结果 |
|---|---|---|---|
* |
匹配任意节点 | //div[@id='u1']/* |
选择所有拥有id=u1的div标签下的所有节点 |
@* |
匹配节点中的任何属性 | //meta[@*] |
选择所有拥有属性的meta标签 |
-
对于通配符
*: 它的作用是匹配任意的节点。比如示例里的//div[@id='u1']/*,就是先找到id为u1的div标签,然后*会匹配这个div标签下的所有子节点,不管这些子节点是什么类型的标签。 -
对于通配符
@*: 它是用来匹配节点的任意属性。像//meta[@*],就是要找出所有带有属性(不管属性名称是什么,只要有属性就行)的meta标签; -
//title[@*]

3.4 选取多个路径
使用 |来表示选择多个路径:
//meta | // title ->> 选择所有的meta和title

4.Xpath语法应用实战
我们在豆瓣电影的影评中,随意找一部电影来抓取相关信息。
- 抓取电影名
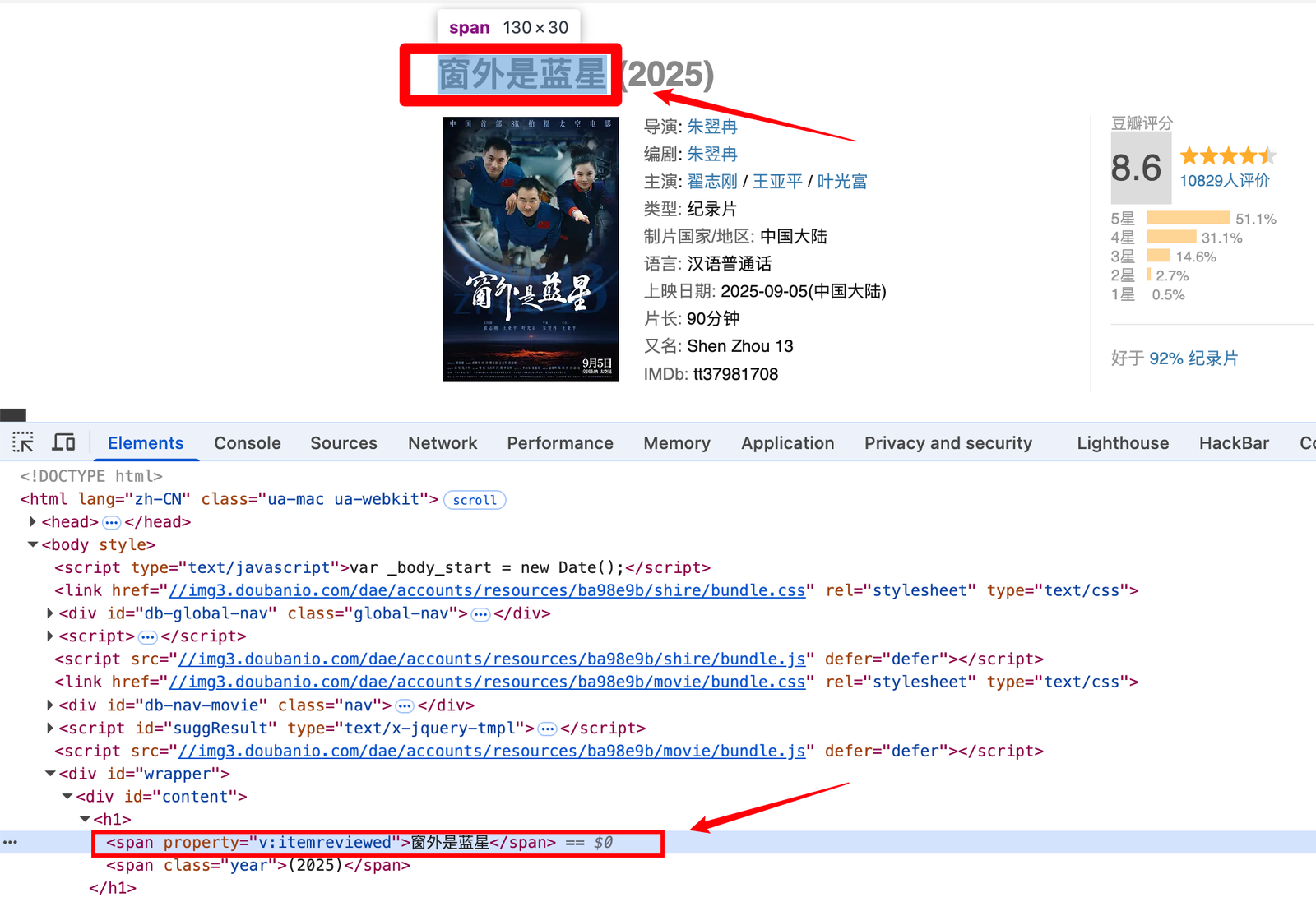
//div[@id="content"]/h1/*[1]

- 抓取导演、编剧等相关信息
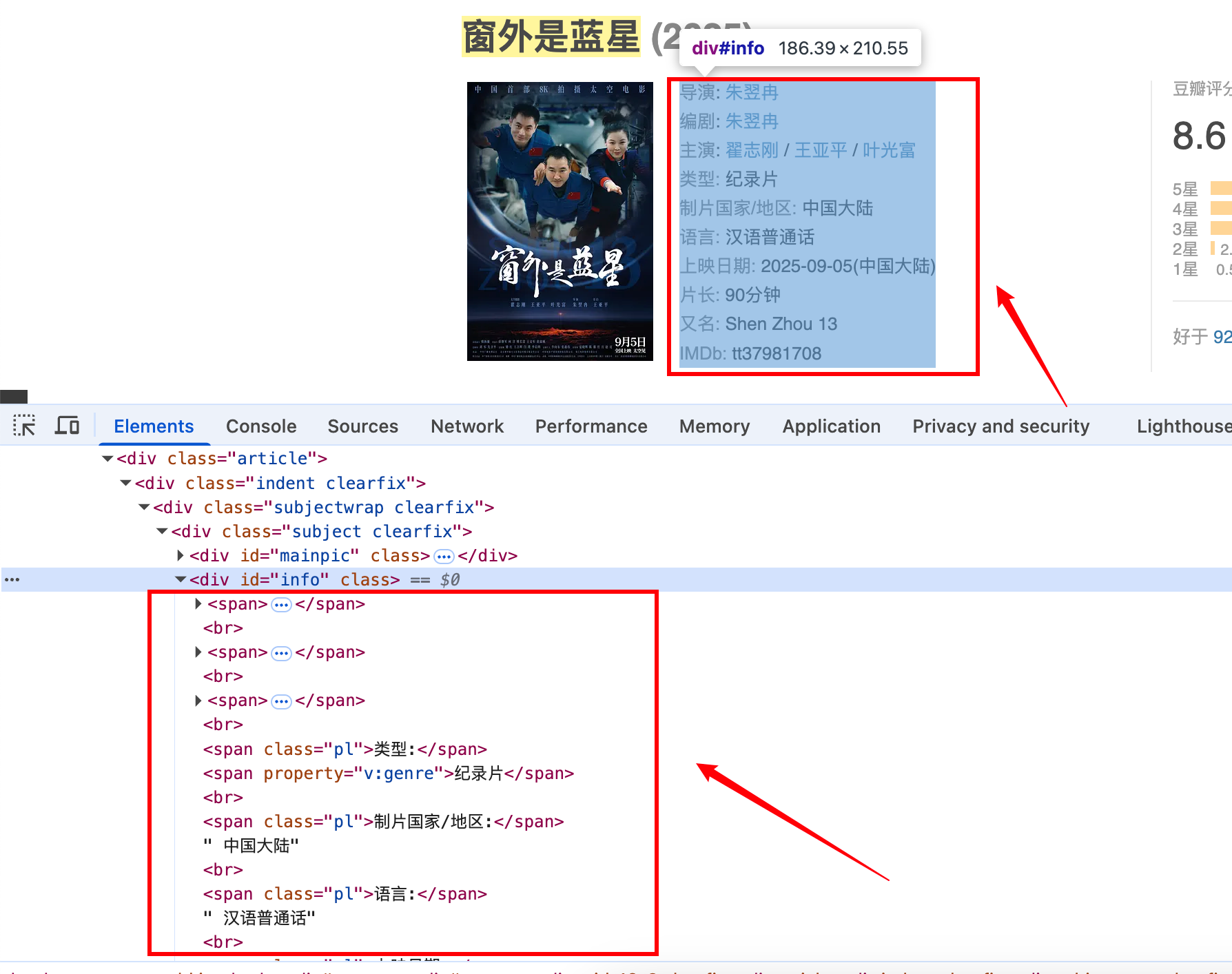
//*[@id="info"]

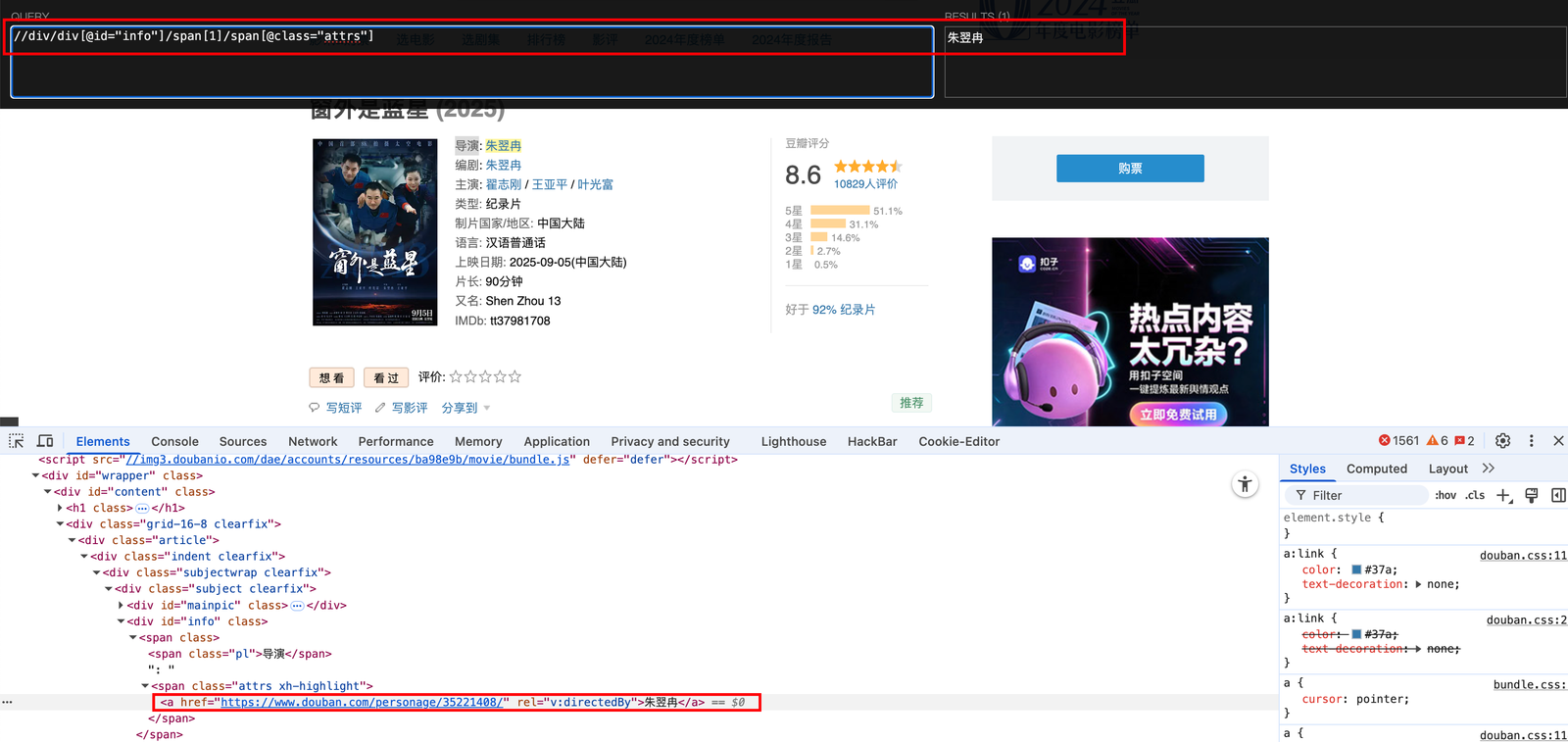
- 单独把导演提取出来
//div/div[@id="info"]/span[1]/span[@class="pl"]

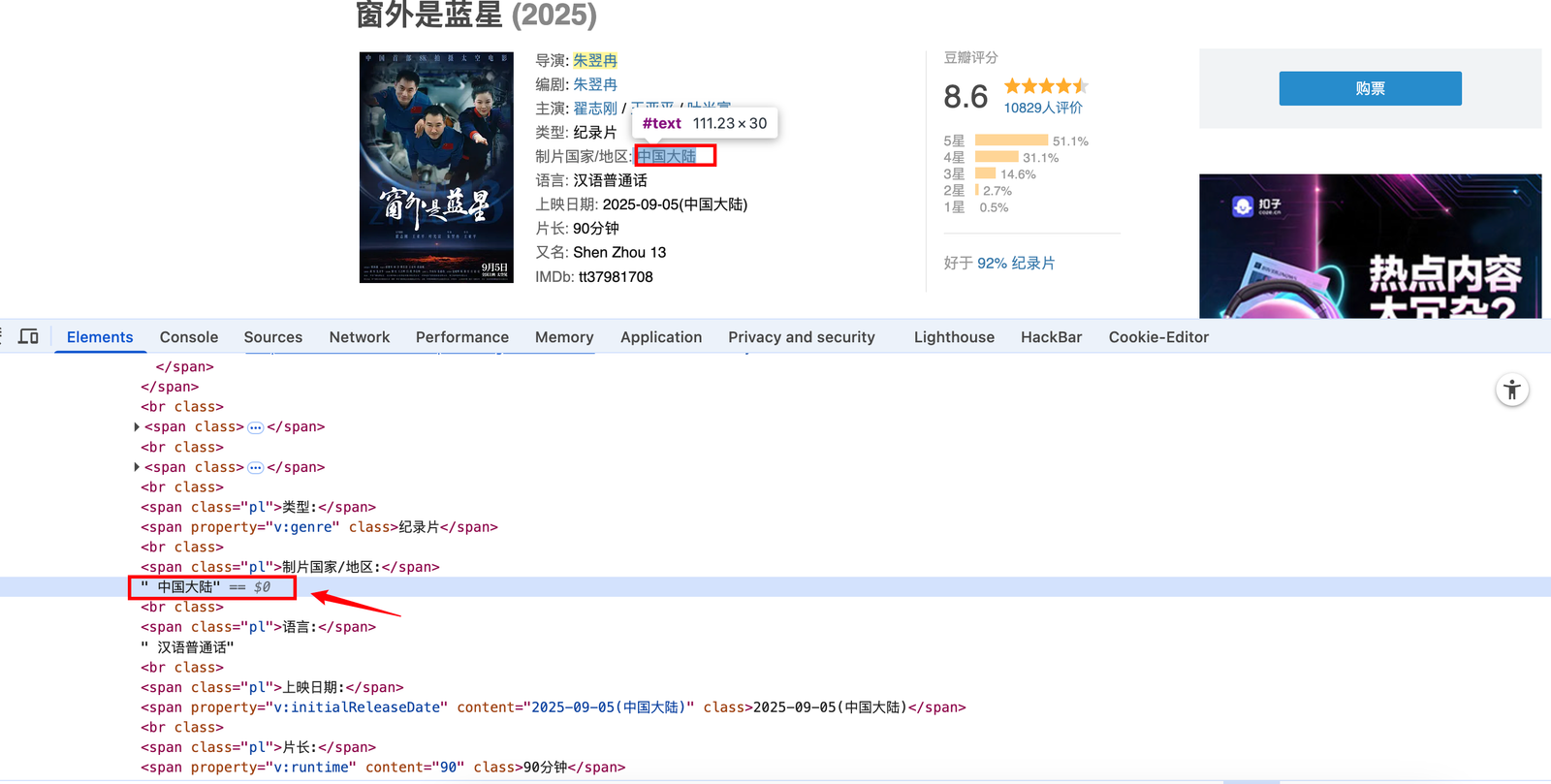
- 提取制片国家/地区:
//span[@class="pl"][2]/following::text()[1]

5.lxml库的安装与介绍
- 安装
lxml 是一个基于 C 扩展的 Python 库,使用 pip 包管理工具直接安装
pip install lxml
- 介绍
lxml 是 Python 中处理 XML 和 HTML 的高性能库,基于成熟的 C 语言库 libxml2 和 libxslt 开发,兼具 Python 的易用性和 C 语言的执行效率。
-
核心特点
- 高效解析: 处理大型文档时速度快、内存占用低
- 容错能力: 能解析不规范的 HTML(如缺失闭合标签的网页)
- 完整标准支持: 全面支持 XPath、XSLT、XML Schema 等
-
典型应用场景
- 网页爬虫(解析 HTML 提取数据)
- XML 文档的生成与解析
简单使用示例:
from lxml import etree
# 解析HTML字符串
html_content = """
<html>
<body>
<div class="container">
<h1>欢迎使用lxml</h1>
<p>这是一个示例段落</p>
<ul>
<li>特性1:高效解析</li>
<li>特性2:容错处理</li>
</ul>
</div>
</body>
</html>
"""
# 创建解析树
tree = etree.HTML(html_content)
# 使用XPath提取数据
title = tree.xpath('//h1/text()')[0]
features = tree.xpath('//ul/li/text()')
print(f"标题:{title}")
print(f"特性列表:{features}")

使用 XPath语法从示例 HTML 中完成以下需求:
- 获取所有的
div标签【节点选取】 - 获取指定的某个
div标签(以id为company - tencent的div为例)【谓语的使用】 - 获取所有的
class为company的div标签 - 获取标签的某个属性值(以第一个
job类的div的data - id属性为例) - 获取
div里面所有的职位信息(包括公司名称、职位名称、薪资、要求、部门)
from lxml import etree
# 解析 HTML 内容
html_content = """
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>招聘信息页面</title>
<style>
.company {
border: 1px solid #ccc;
padding: 10px;
margin-bottom: 15px;
border-radius: 5px;
}
.job {
background-color: #f9f9f9;
padding: 8px;
margin: 5px 0;
border-left: 3px solid #007bff;
}
.high-salary {
color: red;
font-weight: bold;
}
</style>
</head>
<body>
<div class="page-header">
<h1>互联网行业招聘信息汇总</h1>
<p>包含多家知名企业的各类岗位招聘</p>
</div>
<div class="company-list">
<div class="company" id="company-alibaba">
<h2>阿里巴巴集团</h2>
<div class="job" data-id="ali-1">
<h3>Java 高级开发工程师</h3>
<p>薪资:<span class="salary">25k-40k</span>/月</p>
<p>要求:本科及以上学历,5年以上 Java 开发经验,熟悉分布式系统</p>
<p>部门:阿里云事业部</p>
</div>
<div class="job" data-id="ali-2">
<h3>前端技术专家</h3>
<p>薪资:<span class="salary high-salary">30k-50k</span>/月</p>
<p>要求:硕士及以上学历,精通 Vue、React 等框架,有大型项目架构经验</p>
<p>部门:淘宝技术部</p>
</div>
</div>
<div class="company" id="company-tencent">
<h2>腾讯公司</h2>
<div class="job" data-id="tencent-1">
<h3>后端开发工程师</h3>
<p>薪资:<span class="salary">20k-35k</span>/月</p>
<p>要求:本科及以上学历,熟悉 Go 语言,有微服务开发经验优先</p>
<p>部门:微信事业群</p>
</div>
<div class="job" data-id="tencent-2">
<h3>测试开发工程师</h3>
<p>薪资:<span class="salary">18k-30k</span>/月</p>
<p>要求:本科及以上学历,熟悉自动化测试框架,有性能测试经验</p>
<p>部门:腾讯云测试部</p>
</div>
<div class="job" data-id="tencent-3">
<h3>产品经理</h3>
<p>薪资:<span class="salary">22k-38k</span>/月</p>
<p>要求:本科及以上学历,有社交类产品经验,逻辑思维清晰</p>
<p>部门:QQ 产品部</p>
</div>
</div>
<div class="company" id="company-baidu">
<h2>百度公司</h2>
<div class="job" data-id="baidu-1">
<h3>算法工程师</h3>
<p>薪资:<span class="salary high-salary">35k-60k</span>/月</p>
<p>要求:博士学历,机器学习、深度学习方向,有顶会论文优先</p>
<p>部门:人工智能实验室</p>
</div>
<div class="job" data-id="baidu-2">
<h3>大数据开发工程师</h3>
<p>薪资:<span class="salary">25k-45k</span>/月</p>
<p>要求:本科及以上学历,熟悉 Hadoop、Spark 等生态,有大数据平台开发经验</p>
<p>部门:百度大数据部</p>
</div>
</div>
</div>
<div class="footer">
<p>招聘信息仅供参考,具体以企业官方发布为准</p>
</div>
</body>
</html>
"""
html = etree.HTML(html_content)
#1.获取所有的 `div` 标签【节点选取】
print("*"*50+"任务1开始"+"*"*50)
divs = html.xpath('//div')
for div in divs:
div = etree.tostring(div,encoding='utf-8').decode('utf-8') #lxml库中用于将XML/HTML元素转换为字符串的常用操作
print("*"*50)
print(div)
print("*"*50+"任务1完成"+"*"*50)
#2.获取指定的某个 `div` 标签(以 `id` 为 `company - tencent` 的 `div` 为例)【谓语的使用】
print("*"*50+"任务2开始"+"*"*50)
special_divs = html.xpath('//div/div[@id="company-tencent"]')
print(etree.tostring(special_divs[0],encoding='utf-8').decode('utf-8'))
print("*"*50+"任务2完成"+"*"*50)
# 3. 获取所有的 class 为 company 的 div 标签
print("*"*50+"任务3开始"+"*"*50)
company_divs = html.xpath('//div[@class="company"]')
for div in company_divs:
print(etree.tostring(div,encoding='utf-8').decode('utf-8'))
print("*"*50)
print("*"*50+"任务3结束"+"*"*50)
# 4.获取标签的某个属性值(以第一个 `job` 类的 `div` 的 `data - id` 属性为例)
print("*"*50+"任务4开始"+"*"*50)
tag_divs = html.xpath('//div[@class="job"][@data-id]')
print(etree.tostring(tag_divs[0],encoding='utf-8').decode('utf-8'))
print("*"*50+"任务4结束"+"*"*50)
# 5. 获取 div 里面所有的职位信息(包括职位名称、薪资、要求、部门)
print("*"*50+"任务5开始"+"*"*50)
print("*"*50)
company_divs = html.xpath('//div[@class="company"]')
for company_div in company_divs:
company_name = company_div.xpath('.//h2/text()')[0]
print(f"公司名称: {company_name}")
job_divs = company_div.xpath('.//div[@class="job"]')
for job_div in job_divs:
position_name = job_div.xpath('.//h3/text()')
salary = job_div.xpath('.//span[@class]/text()')
requirement = job_div.xpath('.//p/text()')[2]
department = job_div.xpath('.//p/text()')[3]
[print(f"职位名称:{p}") for p in position_name]
print(f"薪资: {salary}")
print(f"{requirement}")
print(f"{department}")
print("*"*50)
print("*"*50+"任务5结束"+"*"*50)
