爬虫提示点:
- 导入必要的库或模块
- 定义网页和请求头
- 获取html页面(注意编码和转码的问题)
- etree解析
- 观察网页源码,查看标签特征
- 编写xpath语法,获取标签内容(文本信息末尾添加/text())
- 存储数据(zip函数双循环)
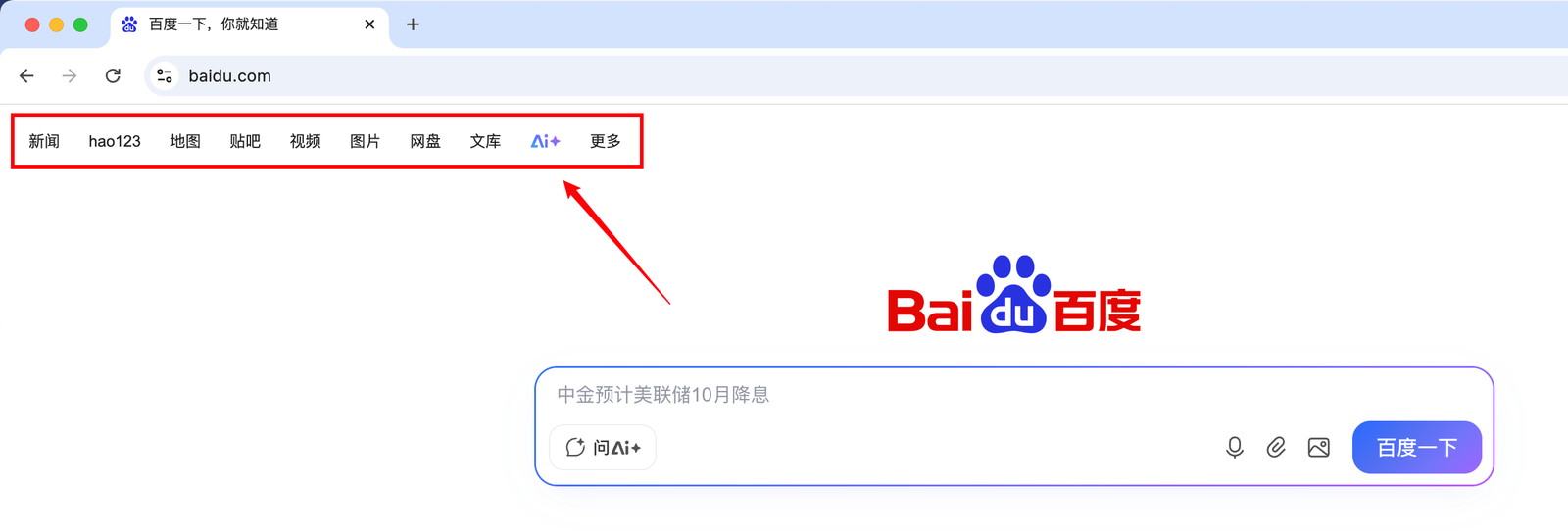
百度页面爬取(🌟)
- 任务: 爬取百度页面左上角新闻等标签和对应链接
- 代码示例
#导入库和模块
import requests
from lxml import etree
#定义网页和请求头
url = "https://www.baidu.com/"
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36'
}
#获取html页面 text是字符串类型
res = requests.get(url, headers=headers)
text = res.text
#将html字符串解析
html = etree.HTML(text)
#编写xpath语法,获取标签内容(文本末尾添加/text())
contents = html.xpath('//div/div[@id="s-top-left"]/a/text()|//div/div[@id="s-top-left"]/div/a/text()|//div/div[@id="s-top-left"]/a/img/@src')
#处理标签信息,有一个标签是img图片手动换成AI字符串,然后加到列表中
keys = []
for item in contents:
item = item.strip()
if "data" in item:
item = "AI"
keys.append(item)
urls = html.xpath('//div/div[@id="s-top-left"]/a/@href|//div/div[@id="s-top-left"]/div/a/@href')
for (key,url) in zip(keys,urls):
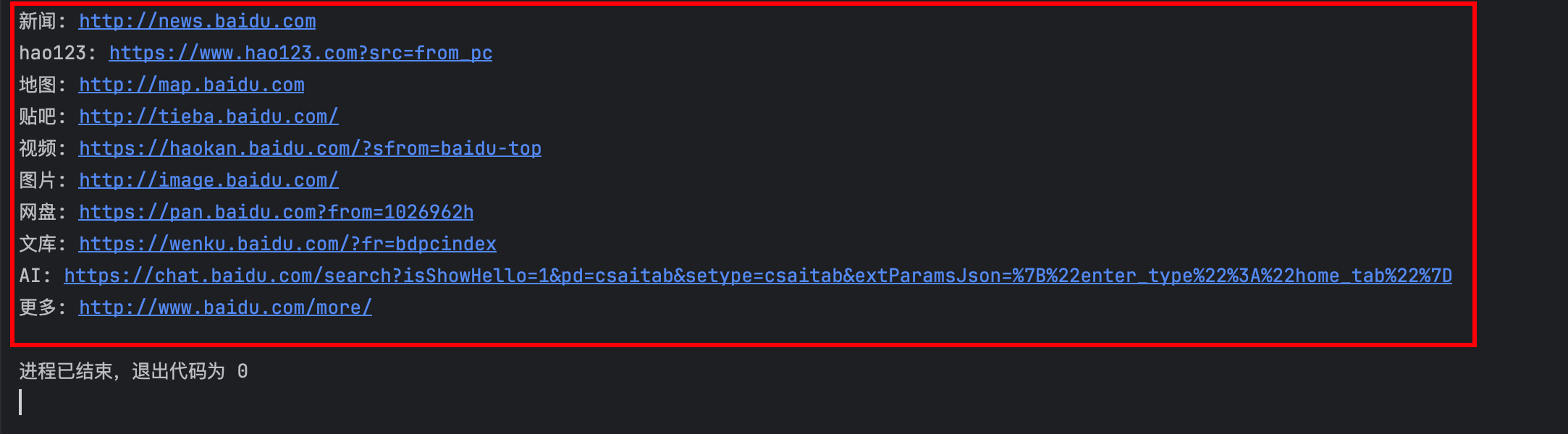
print(f"{key}: {url}")
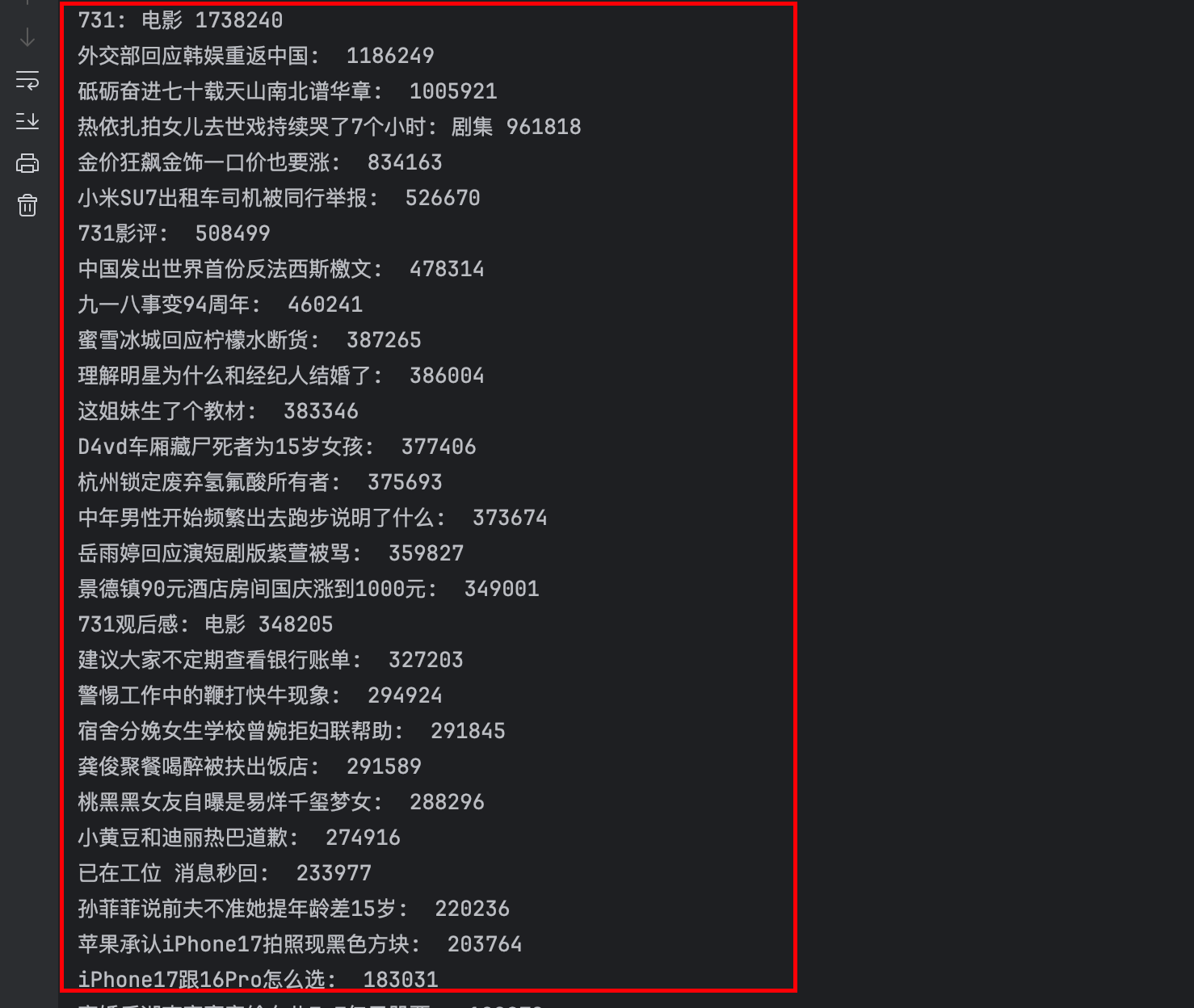
新浪热搜爬取(🌟)
-
任务: 爬取热度榜的内容和热度值
-
hint: 微博有反爬机制,可以复制信息去https://curlconverter.com/python/ 获取请求头和cookies信息
def get_weibo_top():
#定义网页和请求头
url = "https://s.weibo.com/top/summary"
cookies = {
'SUB': '_2AkMfNI0Df8NxqwFRmvkdzGviZY9xzwDEieKpaHzYJRMxHRl-yT9kqmkJtRB6NLSj7MvpaHOQcuWqXYtKn5BN9uhI3rp8',
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9WF0kEihP.YcLRquXMaVBn8b',
'_s_tentry': '-',
'Apache': '4129228658367.541.1758171541219',
'SINAGLOBAL': '4129228658367.541.1758171541219',
'ULV': '1758171541220:1:1:1:4129228658367.541.1758171541219:',
'PC_TOKEN': '9e64eaf90e',
}
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'priority': 'u=0, i',
'sec-ch-ua': '"Chromium";v="140", "Not=A?Brand";v="24", "Google Chrome";v="140"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36',
# 'cookie': 'SUB=_2AkMfNI0Df8NxqwFRmvkdzGviZY9xzwDEieKpaHzYJRMxHRl-yT9kqmkJtRB6NLSj7MvpaHOQcuWqXYtKn5BN9uhI3rp8; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WF0kEihP.YcLRquXMaVBn8b; _s_tentry=-; Apache=4129228658367.541.1758171541219; SINAGLOBAL=4129228658367.541.1758171541219; ULV=1758171541220:1:1:1:4129228658367.541.1758171541219:; PC_TOKEN=9e64eaf90e',
}
#发送请求,获取html页面字符串
res = requests.get(url, headers = headers,cookies = cookies)
text = res.text
# 将html字符串解析
html = etree.HTML(text)
#编写xpath语法
contents = html.xpath('//div//tbody/tr[position()>1]/td/a/text()')
hots = html.xpath('//div//tbody/tr[position()>1]/td/span/text()')
#打印结果
for content,hot in zip(contents,hots):
print(f"{content}: {hot}")
豆瓣电影——基础(🌟)
- 任务: 爬取电影名,评论者和评分,影评
def get_douban_base():
url = "https://movie.douban.com/review/17046342/"
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36'
}
res = requests.get(url, headers = headers)
res.encoding = 'utf-8'
#将html字符串解析
html = etree.HTML(res.text)
title = html.xpath('//div[@class="subject-title"]/a/text()')[0][2:]
reviewer = html.xpath('//header/a/span/text()')[0]
rating = html.xpath('//header/span/@title')[0]
comment = html.xpath('//div/p[@data-align="left"]/text()')[0]
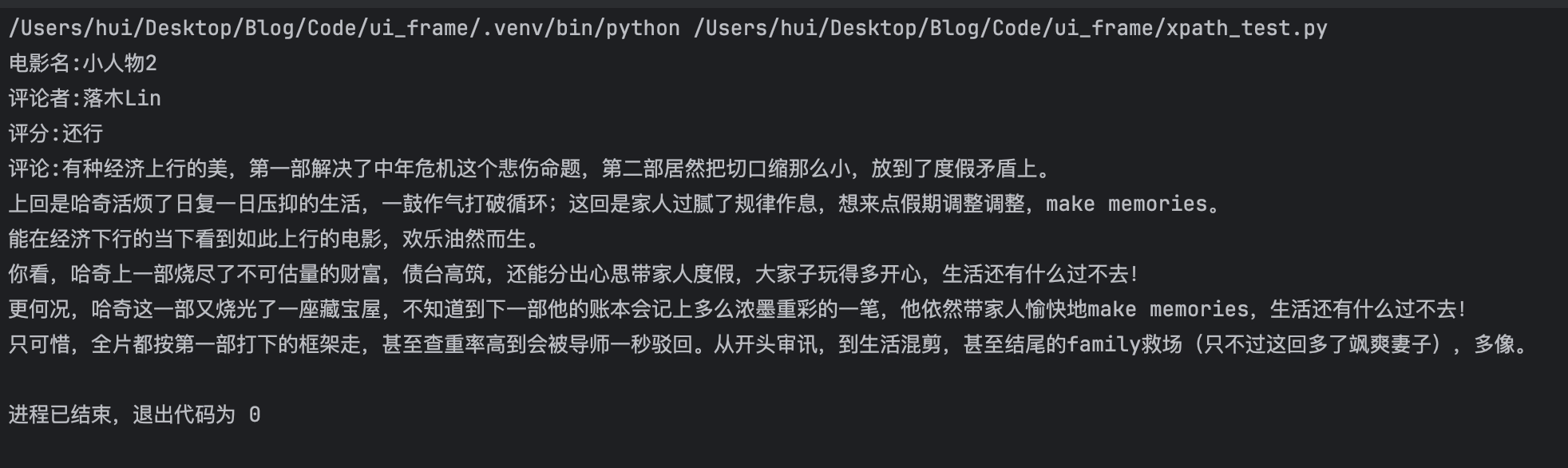
print(f'电影名:{title}')
print(f'评论者:{reviewer}')
print(f'评分:{rating}')
print(f'评论:{comment}')
豆瓣电影——进阶(🌟🌟)
- 任务: 获取豆瓣最受欢迎的影评下的所有的影评数据,共计5页。
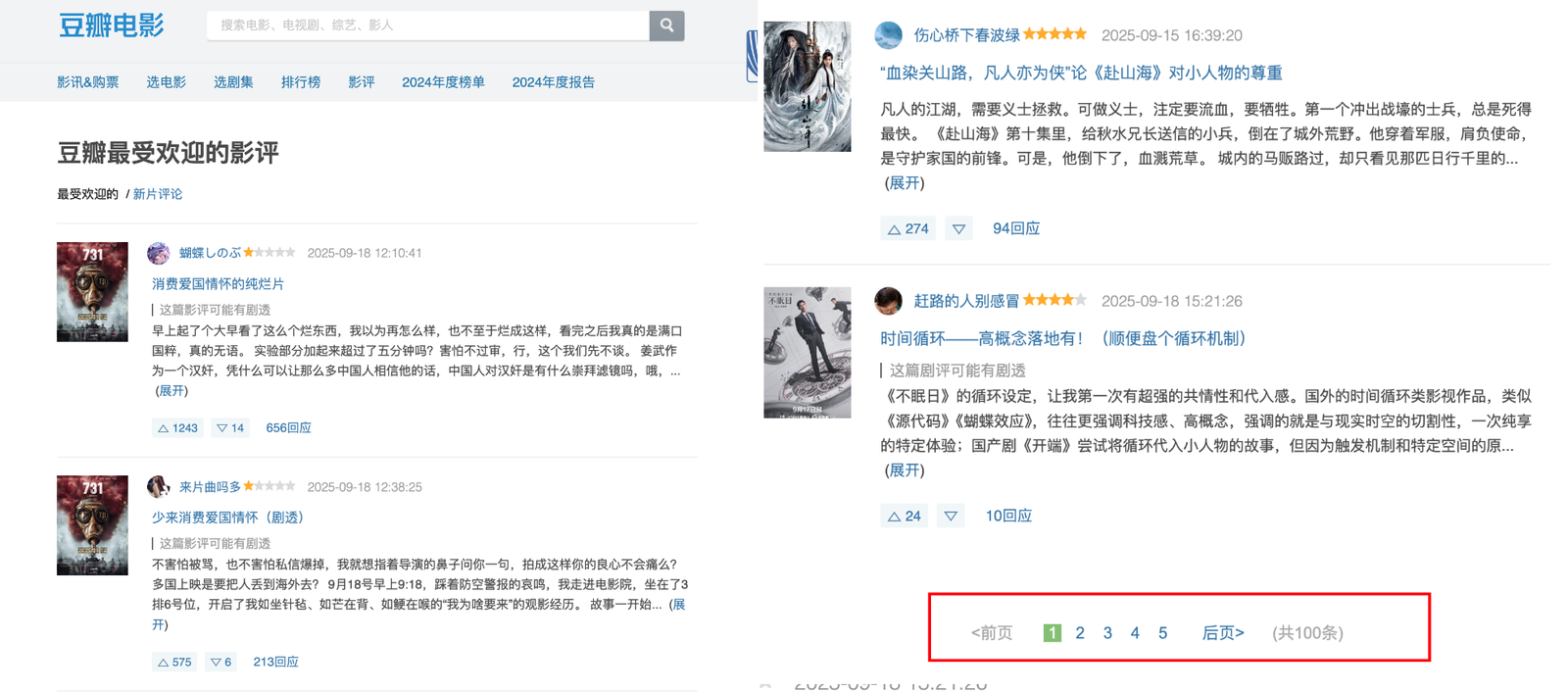
获取共计5页的所有URL
遍历每一页的URL,从每页中得到所有a标签的href属性,得到每部影评的URL
对每部影评的URL进行操作,获取影评数据
import requests
from lxml import etree
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'priority': 'u=0, i',
'sec-ch-ua': '"Chromium";v="140", "Not=A?Brand";v="24", "Google Chrome";v="140"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36',
# 'cookie': '_pk_id.100001.4cf6=b1505f2033e86228.1724424486.; douban-fav-remind=1; _vwo_uuid_v2=D80789444EAD773684E1C35FB38018C50|6074f6aadf78f69aebf2eacd30d13096; viewed="35849693"; bid=JmQQdgtmmQw; ll="118281"; __utmz=30149280.1758009260.6.6.utmcsr=bing|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __utmz=223695111.1758009260.3.1.utmcsr=bing|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __yadk_uid=YoH7BIKEvDrJrPOOMqBFvbX7pE1QwPKP; __utmc=30149280; __utmc=223695111; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1758263973%2C%22https%3A%2F%2Fcn.bing.com%2F%22%5D; _pk_ses.100001.4cf6=1; __utma=30149280.1447128154.1724424486.1758246793.1758263973.9; __utmb=30149280.0.10.1758263973; __utma=223695111.248966808.1724424486.1758246793.1758263973.6; __utmb=223695111.0.10.1758263973',
}
#定义一个列表,获取的信息传送到列表中
douban_infos = []
def get_douban_advance():
url = "https://movie.douban.com/review/best/?start="
for i in range(0,5):
#获取每一页的URL,每一页有10条数据
page_url = url + str(i*20)
#获取html页面,需要编码
res = requests.get(page_url, headers = headers)
res.encoding = 'utf-8'
#etree解析
html = etree.HTML(res.text)
#观察网页源码,查看特征,获取每页URL中每部影评的URL
movie_urls = html.xpath('//h2/a/@href')
#对每部影评的URL进行数据提取,用num显示获取每部影评的过程
num = 1
for movie_url in movie_urls:
get_data(movie_url,i,num)
num += 1
if num == 11:
num = 1
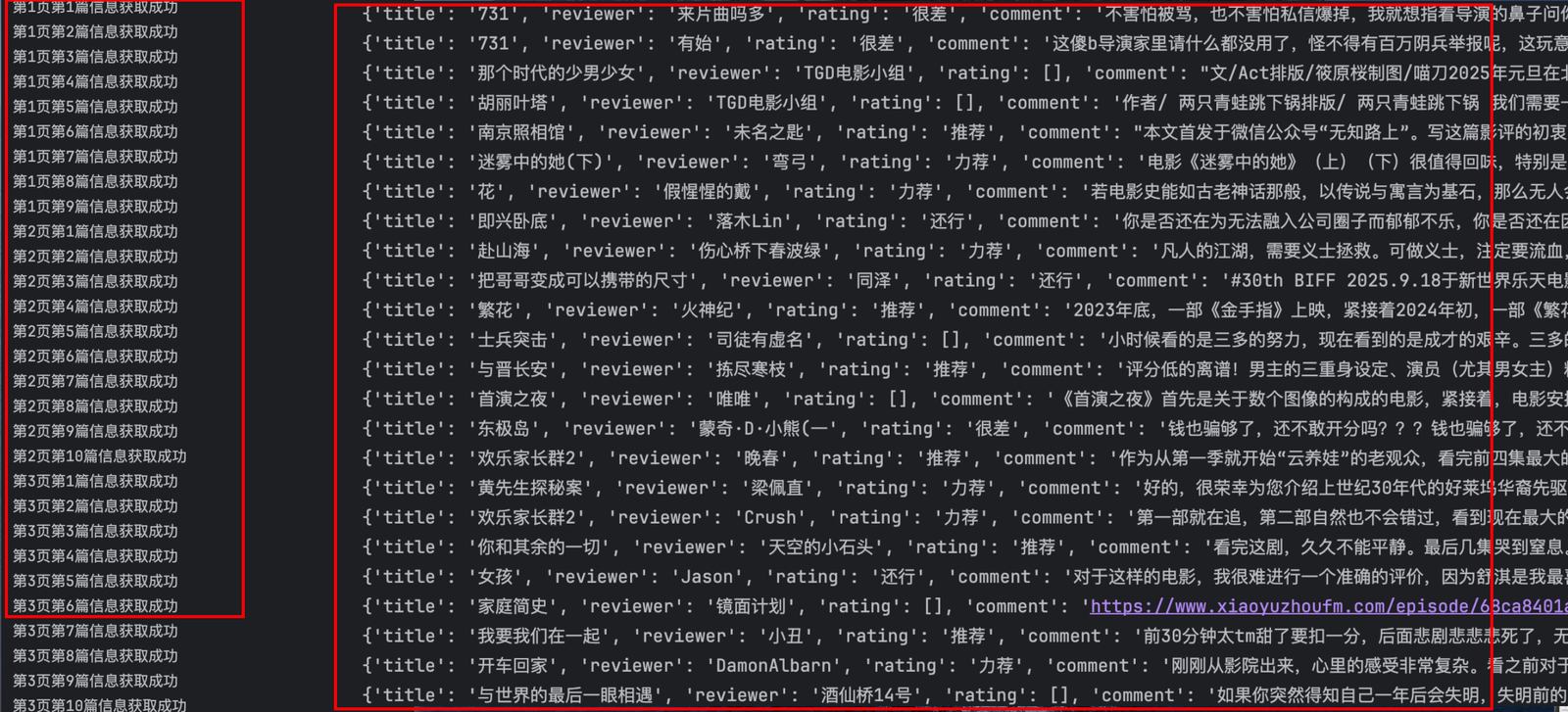
for douban_info in douban_infos:
print(douban_info)
#定义一个新函数,用来获取每部影评的数据,需要传入每部影评的URL
def get_data(url,page,n):
try:
review_id = url.split('/')[-2]
# 发送请求,获取html页面解析
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
html = etree.HTML(res.text)
# 观察网页源码,查看特征,获取每部影评名称、评论者、评分、评论的信息
title = html.xpath('//div[@class="subject-title"]/a/text()')[0][2:]
reviewer = html.xpath('//header/a/span/text()')[0]
rating = html.xpath('//header/span/@title')
if rating:
rating = rating[0]
comment = ''.join(html.xpath(f'//div[@id="link-report-{review_id}"]//p/text()|//div[@id="link-report-{review_id}"]//p/a/text()')).replace('\n', '').replace('\r', '').strip()
douban_info = {
"title":title,
"reviewer":reviewer,
"rating":rating,
"comment":comment,
}
douban_infos.append(douban_info)
print(f"第{page+1}页第{n}篇信息获取成功")
except Exception as e:
print(f"第{page+1}页第{n}篇信息获取失败")
print(f"错误信息:{e}")
if __name__ == "__main__":
get_douban_advance()