
1.聚合函数
在 MySQL 中,聚合函数用于对一组数据进行计算并返回单个结果,通常与 GROUP BY 子句配合使用(也可单独使用,对全表数据聚合)。常用的聚合函数包括 COUNT()、SUM()、AVG()、MAX()、MIN()。
1.1 COUNT(): 统计记录数量
用于计算符合条件的记录行数,有三种常见用法:
COUNT(*): 统计所有记录(包括NULL值)
-- 统计 students 表的总人数
select count(*) as 总人数 from students;
COUNT(字段名): 统计指定字段非NULL值的记录数
-- 统计身高(height)不为 NULL 的学生数量
select count(height) as 身高非空人数 from students;
COUNT(DISTINCT 字段名): 统计指定字段非重复且非NULL的记录数
-- 统计不重复的姓名数量
select count(distinct name) as 不重复姓名数 from students;
1.2 SUM(): 计算数值总和
用于计算指定数值字段的总和(忽略 NULL 值)。
-- 计算所有学生的年龄总和
select sum(age) as 年龄总和 from students;
-- 计算身高大于1.70的学生身高总和
select sum(height) from students where height > 1.7;
1.3 AVG(): 计算平均值
用于计算指定数值字段的平均值(忽略 NULL 值)。
-- 计算所有学生的平均年龄
select avg(age) as 平均年龄 from students;
-- 计算身高非 NULL 的学生平均身高
select avg(age) from students;
1.4 MAX(): 获取最大值
用于获取指定字段的最大值(忽略 NULL 值)。
-- 查找年龄最大的学生年龄
select max(age) as 最大年龄 from students;
-- 查找身高最高的学生身高
select max(height) as 最高身高 from students;
1.5 MIN(): 获取最小值
用于获取指定字段的最小值(忽略 NULL 值)。
-- 查找年龄最小的学生年龄
select min(age) as 最小年龄 from students;
-- 查找身高最矮的学生身高
select min(height) AS 最矮身高 from students;
1.6 聚合函数与 GROUP BY 结合
当需要按某个字段分组聚合时,使用 GROUP BY 子句,聚合函数会对每个分组单独计算结果。
-- 按性别分组,统计每组的人数、平均年龄、最大身高
select gender,count(*) as 人数,avg(age) as 平均年龄,max(height) as 最高身高 from students group by gender;
1.7 小结
-
聚合函数会自动忽略
NULL值,(COUNT(*)除外,它统计所有记录) -
GROUP BY子句必须放在WHERE之后、ORDER BY之前。 -
若使用
GROUP BY,SELECT后只能出现聚合函数或 **GROUP BY中指定的分组字段 **。 -
可通过
HAVING子句对聚合结果进行筛选(类似WHERE,但HAVING用于聚合后过滤):
-- 筛选出人数大于2的性别分组
mysql> select gender,count(*) as 人数, avg(age) as 平均年龄, max(height) as 最高身高 from students group by gender having 人数 > =2;
2.分组查询
在 MySQL 中,分组查询通过 GROUP BY 子句实现,用于将表中的数据按照指定字段的值进行分组,相同值的记录会被归为一组,然后可以对每个组进行聚合计算(如统计数量、求平均值等)。分组查询通常与聚合函数(COUNT、SUM、AVG 等)配合使用,适合对数据进行分类汇总分析。
基本语法:
SELECT 分组字段, 聚合函数(字段)
FROM 表名
[WHERE 条件] -- 分组前筛选数据
GROUP BY 分组字段 -- 按指定字段分组
[HAVING 聚合条件] -- 分组后筛选聚合结果
[ORDER BY 排序字段]; -- 对分组结果排序
2.1: 简单分组(按单个字段分组)
-- 按 gender(性别)分组,统计每个性别的学生数量:
select gender,count(*) as 人数 from students group by gender;
- 分组后,
SELECT后只能出现分组字段和聚合函数,不能出现其他字段(如name、age等非分组字段)。
2.2 多字段分组(按多个字段组合分组)
当单个字段无法满足分组需求时,可以按多个字段组合分组(只有多个字段值完全相同时才会被归为一组)。
-- 按 gender(性别) 和 age(年龄) 分组, 统计每个组合的学生数量:
select gender,age,count(*) as 人数 from students group by gender,age;
2.3: 分组前筛选(WHERE 子句)
先通过 WHERE 筛选出符合条件的记录,再对筛选后的结果进行分组。
-- 筛选出 age > 16 的学生,再按 gender 分组统计人数:
select gender,count(*) as 人数 from students where age > 16 group by gender;
2.4: 分组后筛选(HAVING 子句)
HAVING 子句用于对分组后的结果进行筛选(针对聚合函数的结果),类似 WHERE,但 WHERE 作用于分组前,HAVING 作用于分组后。
-- 按 gender 分组,筛选出 “人数> 2” 的组:
select gender,count(*) as 人数 from students group by gender having 人数 > 2;
2.5 分组 + 排序
对分组后的结果按聚合字段排序,使结果更易读。
-- 按 gender 分组,统计每组的平均年龄,并按平均年龄降序排序:
select gender,count(*) as 人数,avg(age) as 平均年龄 from students group by gender order by 平均年龄 desc;
2.6小结
-
GROUP BY的位置: 必须放在WHERE之后、HAVING和ORDER BY之前。 -
SELECT字段限制:GROUP BY分组后,SELECT后只能出现分组字段和聚合函数,否则会报错或返回不可预期的结果。 -
NULL值的处理:GROUP BY会将所有NULL值视为相同的分组(如示例 1 中gender=NULL的记录被归为一组)。 -
WHERE与HAVING的区别:WHERE: 分组前筛选,不能使用聚合函数(如WHERE COUNT(*) > 2是错误的)。HAVING: 分组后筛选,可使用聚合函数(如HAVING COUNT(*) > 2是正确的)。
3.连接查询方式
3.1 内连接查询
内连接(INNER JOIN) 是 MYSQL中最常用的连接方式,用于获取两个表中满足连接条件的交集数据(即只返回两个表中匹配成功的记录)
内连接的基本语法:
SELECT 字段列表
FROM 表1
INNER JOIN 表2
ON 表1.关联字段 = 表2.关联字段;
演示用表创建:
我们创建两个相关联的表: students(学生表)和 classes(班级表),通过 class_id 字段关联。
-- 创建班级表
CREATE TABLE classes (
id INT PRIMARY KEY AUTO_INCREMENT,
class_name VARCHAR(50) NOT NULL,
teacher VARCHAR(30) NOT NULL
);
-- 创建学生表(包含班级关联字段class_id)
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(30) NOT NULL,
age INT,
class_id INT,
-- 外键关联班级表的id字段
FOREIGN KEY (class_id) REFERENCES classes(id)
);
-- 向班级表插入数据
INSERT INTO classes (class_name, teacher) VALUES
('高一(1)班', '王老师'),
('高一(2)班', '李老师'),
('高一(3)班', '张老师');
-- 向学生表插入数据(包含关联的class_id)
INSERT INTO students (name, age, class_id) VALUES
('张三', 16, 1),
('李四', 17, 1),
('王五', 16, 2),
('赵六', 17, 2),
('孙七', 16, 3),
('周八', 17, NULL); -- 周八没有班级(class_id为NULL,不会被内连接查询到)
内连接查询示例:
-- 示例 1:查询学生及其所属班级信息
mysql> select s.id as 学生id,s.name as 学生姓名,c.class_name as 班级名称,c.teacher as 班主任 from students s inner join classes c on s.class_id = c.id;

-- 示例 2: 查询高一 (2) 班的学生信息
select s.id 学生id,s.name 学生姓名,c.class_name 班级名称,c.teacher 班主任 from students s join classes c on s.class_id = c.id where c.class_name='高一(2)班';

内连接的特点:
- 只返回两个表中满足条件的记录(交集)
- 可以使用表别名(如
s代表students,c代表classes)简化查询 - 连接条件通过
ON子句指定,必须包含两个表的关联字段 - 可以结合
WHERE、ORDER BY等子句进行进一步筛选和排序
3.2 左连接查询
左连接(LEFT JOIN 或 LEFT OUTER JOIN)是 MySQL 中常用的表连接方式,用于查询左表(JOIN 关键字左侧的表)的所有记录,以及右表中与左表满足连接条件的匹配记录。若右表无匹配记录,会用 NULL 填充右表的字段。
左连接基本语法:
SELECT 字段列表
FROM 左表
LEFT JOIN 右表
ON 连接条件;
ON后指定连接条件(如两表的关联字段匹配关系)
-- 左连接查询所有学生及其对应的班级信息
select s.id 学生id,s.name 学生姓名,c.class_name 班级名称,c.teacher 班主任 from students s left join classes c on s.class_id = c.id;

特点:
- 左表数据全保留: 无论右表是否有匹配记录,左表的所有行都会出现在结果中。
- 右表缺省用 NULL 填充: 若右表无满足连接条件的记录,右表字段显示为 NULL。
- 与内连接的区别: 内连接(JOIN)只保留两表匹配的记录,而左连接强制保留左表全部数据,适合需 "包含左表所有数据" 的场景(如查询所有学生,无论是否有班级)。
3.3 右连接查询
右连接(RIGHT JOIN)与左连接逻辑相反,它会返回右表(JOIN 关键字右侧的表)的所有记录,以及左表中与右表满足连接条件的匹配记录。若左表无匹配记录,会用 NULL 填充左表的字段。
基本语法:
SELECT 字段列表
FROM 左表
RIGHT JOIN 右表
ON 连接条件;
- 核心是保证右表的所有记录都被保留,左表仅显示匹配项。
-- 假设我们新增一个没有学生的班级:
INSERT INTO classes (class_name, teacher) VALUES ('高一(4)班', '刘老师');
-- 执行右连接查询:
mysql> SELECT c.id AS 班级ID,c.class_name AS 班级名称,s.name AS 学生姓名,s.age AS 学生年龄 FROM students s RIGHT JOIN classes c ON s.class_id = c.id;

特点:
- 右表数据全保留: 无论左表是否有匹配记录,右表的所有行都会出现在结果中。
- 左表缺省用 NULL 填充: 若左表无满足连接条件的记录,左表字段显示为 NULL。
- 适用场景: 适合需要 "以右表为基准,关联查询左表数据" 的场景,例如 "查询所有班级及其学生信息,包括没有学生的班级"。
- 与左连接的转换: 右连接可通过交换表的位置转换为左连接(如
A RIGHT JOIN B等价于B LEFT JOIN A),实际使用中左连接更常用。
3.4 自连接查询
自连接(Self Join)是一种特殊的表连接方式,指同一张表与自身进行连接,通过给表起不同的别名,将一张表虚拟成两张 “不同” 的表来处理,从而实现对表中数据的关联查询(如查询同一表中具有层级关系、关联关系的数据)。
例如在学生表中,若存在 “班长” 与 “普通学生” 的层级关系(可通过monitor_id字段关联班长的id),就可以用自连接查询每个学生及其对应的班长信息。
基本语法:
SELECT 字段列表
FROM 表名 别名1
JOIN 表名 别名2 -- 同一张表用不同别名
ON 别名1.关联字段 = 别名2.关联字段; -- 连接条件(表内字段的关联关系)
- 核心是通过别名区分 “两张虚拟表”(实际为同一张表)
- 可结合
INNER JOIN、LEFT JOIN等连接类型使用
示例:
假设我们扩展students表,增加monitor_id字段表示该学生的班长 ID(关联自身的id):
-- 扩展表结构
ALTER TABLE students ADD COLUMN monitor_id INT;
-- 更新数据(假设张三、赵六是班长,monitor_id为NULL表示自己是班长)
UPDATE students SET monitor_id = 1 WHERE id IN (2,3); -- 李四、王五的班长是张三(id=1)
UPDATE students SET monitor_id = 4 WHERE id = 5; -- 孙七的班长是赵六(id=4)
-- 用自连接查询 “学生及其对应班长姓名”:
mysql> select s.id 学生id, s.name 学生姓名, m.monitor_id 班长id, m.name 班长姓名 from students s left join students m on s.monitor_id = m.id;

3.5 子查询
子查询(Subquery)是指嵌套在另一个 SQL 查询中的查询语句,也称为内层查询。外层查询可以使用子查询的结果作为条件、数据源或计算依据,实现更复杂的查询逻辑。
基本语法:
子查询的基本结构是将一个查询语句放在另一个查询的WHERE、FROM或SELECT子句中:
-- 外层查询使用子查询的结果作为条件
SELECT 字段列表
FROM 表名
WHERE 字段 运算符 (
SELECT 字段列表 -- 子查询(内层查询)
FROM 表名
WHERE 条件
);
- 子查询需用括号
()包裹 - 可返回单个值、多个值或多行多列数据,根据返回结果类型适配外层查询的运算符(如
=、IN、EXISTS等)
示例:
-- 子查询返回单个值(用于比较)
-- 查询年龄大于所有学生平均年龄的学生
select name,age from students where age > (select avg(age) from students);

-- 子查询返回多个值(用IN匹配)
-- 查询“高一(1)班”的所有学生
mysql> select * from students where class_id in (select id from classes where class_name = '高一(1)班');

-- 子查询作为数据源(用FROM子句)
-- 查询每个班级的学生人数(子查询作为临时表)
select c.class_name 班级名字,ifnull(temp.student_count, 0) 学生数量 from classes c left join(select class_id,count(*) as student_count from students group by class_id) temp on c.id = temp.class_id;

-- 用EXISTS判断子查询是否有结果
-- 查询有学生的班级
mysql> select class_name from classes c where exists(select 1 from students s where s.class_id = c.id);
4.数据库设计之三范式
在 MySQL 数据库设计中,三大范式(Normal Forms, NF) 是指导数据表结构优化的核心原则,其目标是减少数据冗余、避免更新异常(插入 / 删除 / 修改异常),确保数据的一致性和完整性。三大范式从低到高逐步严格,通常满足第三范式即可应对绝大多数业务场景,更高阶的范式(如 BCNF、4NF)则适用于特殊复杂场景。
**函数依赖: **
在理解范式前,需先掌握函数依赖: 设数据表中的两个属性集 A 和 B,若对于 A 中的每一个值,B 中都有唯一确定的值与之对应,则称 “A 函数决定 B” 或 “B 函数依赖于 A”,记为 A → B。
- 例:在
学生表中,“学号” 唯一确定 “姓名” 和 “班级”,即学号 → 姓名、学号 → 班级。 - 关键术语:
- 主键(候选键): 能唯一决定表中所有其他属性的属性集(如上例中的 “学号”)。
- 非主属性: 除主键外的其他属性(如上例中的 “姓名”“班级”)。
4.1 第一范式(1NF): 原子性原则
定义: 数据表中的每一列(属性)必须是不可再分的原子值,即列不能包含多个子属性或复合值。
1NF 是数据库设计的最低要求,不满足 1NF 的结构甚至不能称为 “关系型数据表”。
反例(不满足 1NF)
假设设计学生信息表如下,其中 “联系方式” 列包含 “电话” 和 “邮箱” 两个子属性,不符合原子性:
| 学号 | 姓名 | 联系方式 |
|---|---|---|
| 2024001 | 张三 | 13800138000, zhang@xxx.com |
| 2024002 | 李四 | 13900139000, li@xxx.com |
正例(满足 1NF)
将 “联系方式” 拆分为独立的 “电话” 和 “邮箱” 列,确保每列值不可再分:
| 学号 | 姓名 | 电话 | 邮箱 |
|---|---|---|---|
| 2024001 | 张三 | 13800138000 | zhang@xxx.com |
| 2024002 | 李四 | 13900139000 | li@xxx.com |
4. 2第二范式(2NF): 消除部分依赖
前提: 必须先满足第一范式(1NF)。
定义:数据表中的每一个非主属性, 必须完全函数依赖于主键(而非依赖主键的某一部分,即 “部分依赖”)。
2NF 主要解决 “复合主键” 场景下的冗余问题 —— 若主键由多个属性组成(如选课表的主键为 “学号 + 课程号”),非主属性不能仅依赖主键中的某一个属性。
反例(不满足 2NF)
设计选课表,主键为 “学号 + 课程号”,但 “学生姓名” 仅依赖 “学号”,“课程名称” 仅依赖 “课程号”(存在部分依赖):
| 学号 | 课程号 | 学生姓名 | 课程名称 | 成绩 |
|---|---|---|---|---|
| 2024001 | C001 | 张三 | 数学 | 90 |
| 2024001 | C002 | 张三 | 英语 | 85 |
| 2024002 | C001 | 李四 | 数学 | 88 |
正例(满足 2NF)
拆分表为 3 个独立表,消除部分依赖:
学生表(主键: 学号): 存储学生基本信息
| 学号 | 学生姓名 |
|---|---|
| 2024001 | 张三 |
| 2024002 | 李四 |
课程表(主键:课程号):存储课程基本信息
| 课程号 | 课程名称 |
|---|---|
| C001 | 数学 |
| C002 | 英语 |
选课表(主键:学号 + 课程号): 仅存储选课关系和成绩(非主属性 “成绩” 完全依赖复合主键)
| 学号 | 课程号 | 成绩 |
|---|---|---|
| 2024001 | C001 | 90 |
| 2024001 | C002 | 85 |
| 2024002 | C001 | 88 |
4.3 第三范式(3NF): 消除传递依赖
前提: 必须先满足第二范式(2NF)。
定义: 数据表中的每一个非主属性, 必须不传递依赖于主键(即非主属性之间不能存在 “非主属性 A → 非主属性 B” 的依赖关系)。
3NF解决 “非主属性通过其他非主属性间接依赖主键” 的问题,进一步减少冗余。
反例(不满足 3NF)
设计学生表,主键为 “学号”,但 “班级辅导员” 依赖 “班级”,“班级” 依赖 “学号”(存在传递依赖:学号 → 班级 → 班级辅导员):
| 学号 | 学生姓名 | 班级 | 班级辅导员 |
|---|---|---|---|
| 2024001 | 张三 | 一班 | 王老师 |
| 2024002 | 李四 | 一班 | 王老师 |
| 2024003 | 王五 | 二班 | 李老师 |
正例(满足 3NF)
拆分表为 2 个独立表,消除传递依赖:
1.学生表(主键: 学号):仅存储学生与班级的直接关联
| 学号 | 学生姓名 | 班级 |
|---|---|---|
| 2024001 | 张三 | 一班 |
| 2024002 | 李四 | 一班 |
| 2024003 | 王五 | 二班 |
2.班级表(主键:班级): 存储班级与辅导员的关联
| 班级 | 班级辅导员 |
|---|---|
| 一班 | 王老师 |
| 二班 | 李老师 |
小结:
| 范式 | 核心要求(前提: 满足前一范式) | 解决的问题 | 关键目标 |
|---|---|---|---|
| 1NF | 列值原子化(不可再分) | 非关系型结构问题 | 确保数据表合法性 |
| 2NF | 非主属性完全依赖主键 | 部分依赖导致的冗余 | 消除部分依赖 |
| 3NF | 非主属性不传递依赖主键 | 传递依赖导致的冗余 | 消除传递依赖 |
4.4 E-R模型的介绍
E-R模型主要由三个要素构成: 实体(Entity)、属性(Attribute) 和关系(Relationship),通过 E-R 图(实体 - 关系图)直观呈现。
E-R模型的效果图:
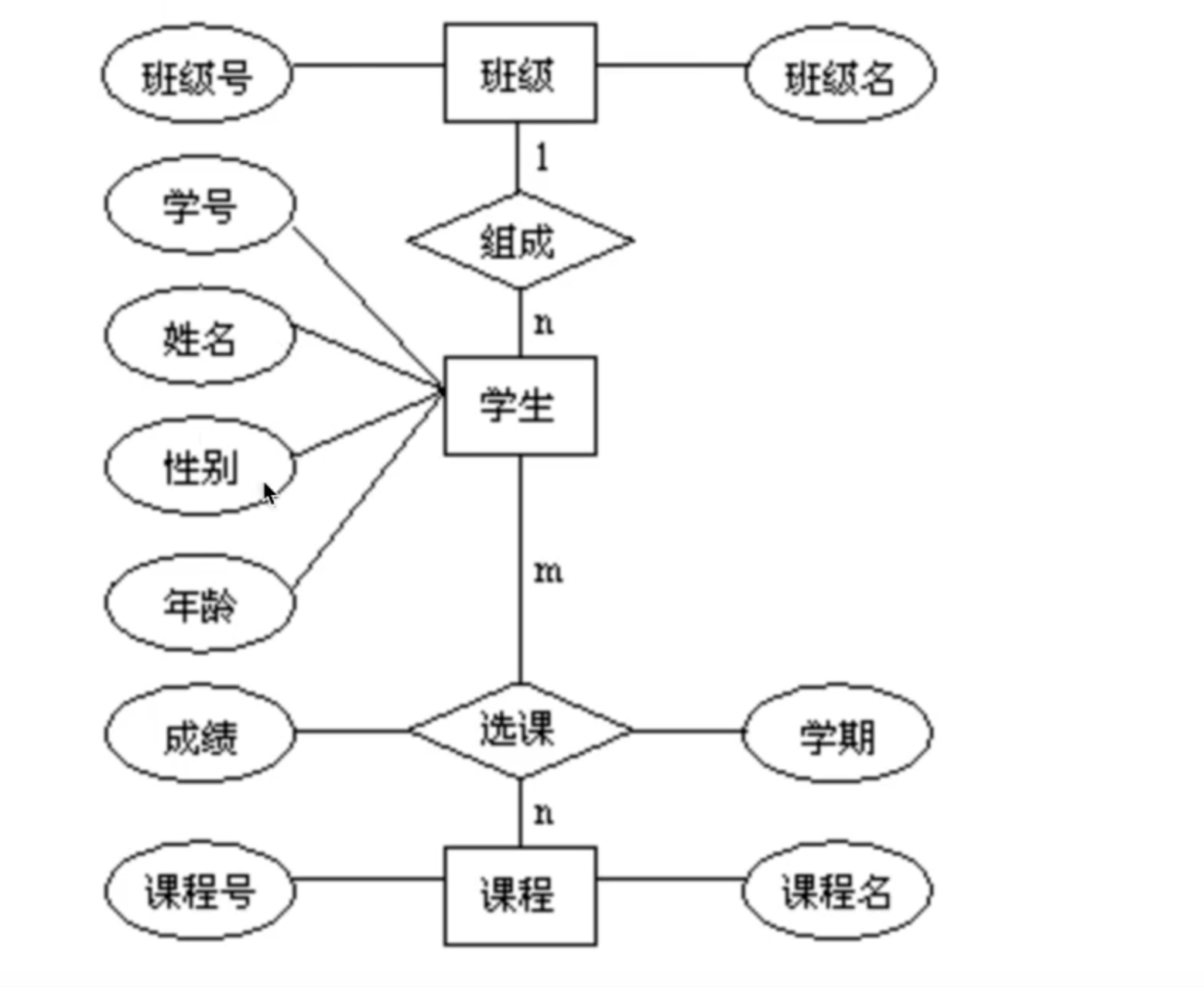
E-R 图表示:
- 用矩形表示实体,矩形内标注实体名称(如 “班级”、“学生”)。
- 用椭圆形表示属性,通过连线与对应实体关联,椭圆内标注属性名称(如 “班级号”、“班级名”)。
- 用菱形表示关系,菱形内标注关系名称(如 “选课”、“组成”),通过连线与关联的实体连接,并在连线上标注关系的基数(如 1:1、1:N、M:N)。
- 1:1 关系: 通常将一个实体的主键作为另一个表的外键。
- 1:N 关系:在 “多” 的一方表中加入 “一” 方的主键作为外键(如 “学生表” 中加入 “班级号” 作为外键关联 “班级表”)。
- M:N 关系: 需新增一个 “中间表”,存储两个实体的主键作为联合主键(或外键),并可包含关系的属性(如 “选课表” 包含 “学号”“课程号” 外键,及 “成绩” 属性)。
5.外键约束写详解
5.1 外键约束的作用
外键约束式MySQL中用于维护表与表之间关联关系的重要机制,主要作用包括:
- 保证数据完整性: 确保子表中引用的数据在父表中一定存在
- 维护数据一致性: 当父表中的数据发生变化时,可通过设置不同的外键动作(如级联删除、级联更新等) 自动维护子表的数据
5.2 为已存在的字段添加外键约束
当需要为已存在的表添加外键约束时,可使用 ALTER TABLE 语句,语法如下:
ALTER TABLE 子表名
ADD CONSTRAINT 外键约束名
FOREIGN KEY (子表外键字段名)
REFERENCES 父表名(父表被引用字段名)
[ON DELETE 动作]
[ON UPDATE 动作];
假设已存在 classes 表(父表)和 students 表(子表),现在为 students 表的 class_id 字段添加外键约束:
mysql> alter table students
-> add constraint fk_students_classes
-> foreign key (class_id)
-> references classes(id)
-> ;
- 添加外键前,确保子表中已存在的外键字段值在父表中都能找到对应的值
- 子表外键字段与父表被引用字段的数据类型必须完全一致
- 父表被引用字段必须是主键或唯一索引
5.3 在创建数据表时设置外键约束
在创建数据表时设置外键语法:
CREATE TABLE 子表名 (
字段1 数据类型 [约束],
字段2 数据类型 [约束],
...,
[CONSTRAINT 外键约束名]
FOREIGN KEY (子表外键字段名)
REFERENCES 父表名(父表被引用字段名)
[ON DELETE 动作]
[ON UPDATE 动作]
);
创建子表 head_teacher 并同时设置外键约束
mysql> create table head_teacher(
-> id int primary key auto_increment,
-> name varchar(20) not null,
-> c_id int not null,
-> constraint fk_head_teacher_classes
-> foreign key (c_id)
-> references classes(id)
-> );
5.4 删除外键约束
删除外键约束需使用外键约束名,语法如下:
ALTER TABLE 子表名
DROP FOREIGN KEY 外键约束名;
示例:
删除 students 表中的 fk_students_classes 外键约束:
ALTER TABLE students DROP FOREIGN KEY fk_students_classes;
5.5 小结
- 外键约束的核心作用是保证数据的引用完整性,防止出现无效的关联数据。
- 可为已存在的表添加外键约束,使用
ALTER TABLE ... ADD CONSTRAINT语句。 - 可在创建表时直接定义外键约束,明确表间关系。
- 外键动作明确了当父表中的被引用记录发生删除(ON DELETE)或更新(ON UPDATE)操作时,子表中关联记录的处理规则。
6.分组和聚合函数的组合使用
6.1 数据准备
-- 创建 "京东" 数据库
create database jing_dong charset=utf8;
-- 使用 "京东" 数据库
use jing_dong;
-- 创建一个商品 goods 数据表
create table goods (
id int unsigned primary key auto_increment not null,
name varchar (150) not null,
cate_name varchar (40) not null,
brand_name varchar (40) not null,
price decimal (10,3) not null default 0,
is_show bit not null default 1,
is_saleoff bit not null default 0
);
-- 向goods表中插入数据
Insert into goods values (0,'r510vc15.6 英寸笔记本','笔记本','华硕','3399',default,default);
insert into goods values (0,'y400n14.0 英寸笔记本电脑','笔记本','联想','4999',default,default);
insert into goods values (0,'g150th15.6 英寸游戏本','游戏本','雷神','8499',default,default);
insert into goods values (0,'x550cc15.6 英寸笔记本','笔记本','华硕','2799',default,default);
insert into goods values (0,'x240 超极本','超级本','联想','4880',default,default);
insert into goods values (0,'u330p13.3 英寸超极本','超级本','联想','4299',default,default);
insert into goods values (0,'svp13226scb 触控超极本','超级本','索尼','7999',default,default);
insert into goods values (0,'ipadmini7.9 英寸平板电脑','平板电脑','苹果','1998',default,default);
insert into goods values (0,'ipadair9.7 英寸平板电脑','平板电脑','苹果','3388',default,default);
insert into goods values (0,'ipadmini 配备 retina 显示屏','平板电脑','苹果','2788',default,default);
insert into goods values (0,'ideacentrec34020 英寸一体电脑','台式机','联想','3499',default,default);
insert into goods values (0,'vostro3800-r1206 台式电脑','台式机','戴尔','2899',default,default);
insert into goods values (0,'imacme086ch/a21.5 英寸一体电脑','台式机','苹果','9188',default,default);
insert into goods values (0,'at7-7414lp 台式电脑 linux)','台式机','宏碁','3699',default,default);
insert into goods values (0,'z220sfff4f06pa 工作站','服务器 / 工作站','惠普','4288',default,default);
insert into goods values (0,'poweredgeii 服务器','服务器 / 工作站','戴尔','5388',default,default);
insert into goods values (0,'macpro 专业级台式电脑','服务器 / 工作站','苹果','28888',default,default);
insert into goods values (0,'hmz-t3w 头戴显示设备','笔记本配件','索尼','6999',default,default);
insert into goods values (0,'商务双肩背包','笔记本配件','索尼','99',default,default);
insert into goods values (0,'x3250m4 机架式服务器','服务器 / 工作站','ibm','6888',default,default);
insert into goods values (0,'商务双肩背包','笔记本配件','索尼','99',default,default);
- 表结构说明:
- id 表示主键,自增
- name 表示商品名称
- cate_name 表示分类名称
- brand_name 表示品牌名称
- price 表示价格
- is_show 表示是否显示
- is_saleoff 表示是否售完
6.2 练习
Example1:
-- 查询类型 cate_name 为 '超级本' 的商品名称、价格
mysql> select name,price from goods where cate_name = '超级本';
Example2:
-- 显示商品的分类
mysql> select distinct(cate_name) from goods;
-- 解法2:
mysql> select cate_name from goods group by cate_name;
Example3:
-- 求所有电脑产品的平均价格,并且保留两位小数
mysql> select round(avg(price),2) from goods;
Example4:
-- 显示每种商品的平均价格
mysql> select cate_name,round(avg(price),2) from goods group by cate_name;
Example5:
-- 查询每种类型的商品中 最贵、最便宜、平均价、数量
mysql> select cate_name,max(price) as 最贵价格,min(price) as 最便宜价格, avg(price) as 平均价格, count(*) as 商品数量 from goods group by cate_name;
Exmaple6:
-- 查询所有价格大于平均价格的商品,并且按价格降序排序
-- WHERE:用于筛选原始数据行,不能使用聚合函数。
mysql> select id,name,price from goods where price > (select avg(price) from goods) order by price desc;
