
1.将查询结果插入到其它表中
在数据库操作中,“将查询结果插入到其他表” 是非常常用的场景,核心是利用 INSERT ... SELECT 语法,将一个查询(SELECT)的结果集作为数据源,直接插入到目标表中。该操作广泛应用于数据备份、报表生成、数据迁移、批量同步等场景。
1.1 创建商品分类表
-- 创建商品分类表
create table good_cates( id int not null primary key auto_increment, name varchar(50) not null );
1.2 把goods表中的商品分类添加到商品分类表
-- 查询goods表中商品的分类信息
select cate_name from goods group by cate_name;
-- 将查询结果插入到good_cates表中
insert into good_cates(name) select cate_name from goods group by cate_name;
-- 添加移动设备分类信息
insert into good_cates (name) values('移动设备');
2.使用连接更新表中某个字段数据
2.1 更新goods表中的商品分类信息
通过 UPDATE ... JOIN 语法,可灵活实现基于多表关联的字段更新,这在数据规范化、批量调整、跨表同步等场景中非常高效。
- 将
goods表中的分类名称更改成商品分类表中对应的分类id
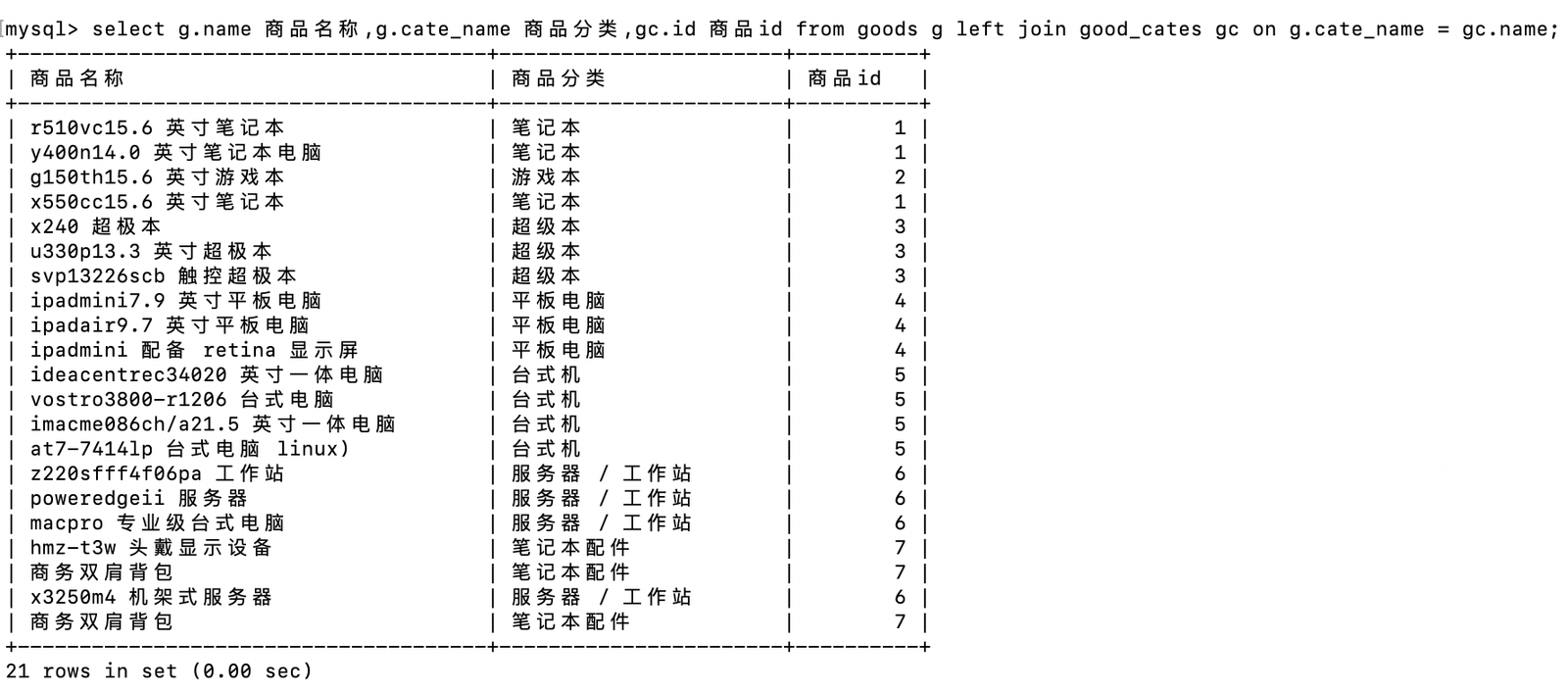
-- 查看goods表中商品分类名称对应商品分类id
select g.name 商品名称,g.cate_name 商品分类,gc.id 商品id from goods g left join good_cates gc on g.cate_name = gc.name;
-- 更新:将goods表的cate_name字段改为good_cates表的id
update goods g left join good_cates gc on g.cate_name = gc.name set g.cate_name = gc.id;
3.创建表并给某个字段添加数据
在 MySQL 中,CREATE TABLE ... SELECT 语法可以实现创建表的同时插入数据,核心是通过 SELECT 语句查询出要插入的数据,并将其填充到新表的对应字段中。
3.1 创建品牌表
-- 查询品牌信息
select brand_name from goods group by brand_name;
-- 通过crete table ... select来创建数据表并且同时插入数据
-- 创建商品分类表,注意: 需要对brand_name 用 as起别名,否则name字段就没有值
create table good_brands ( id int unsigned primary key auto_increment, name varchar(40) not null) select brand_name as name from goods group by brand_name;
- 一次性完成 "建表 + 数据插入"

3.2 更新goods表中的品牌信息
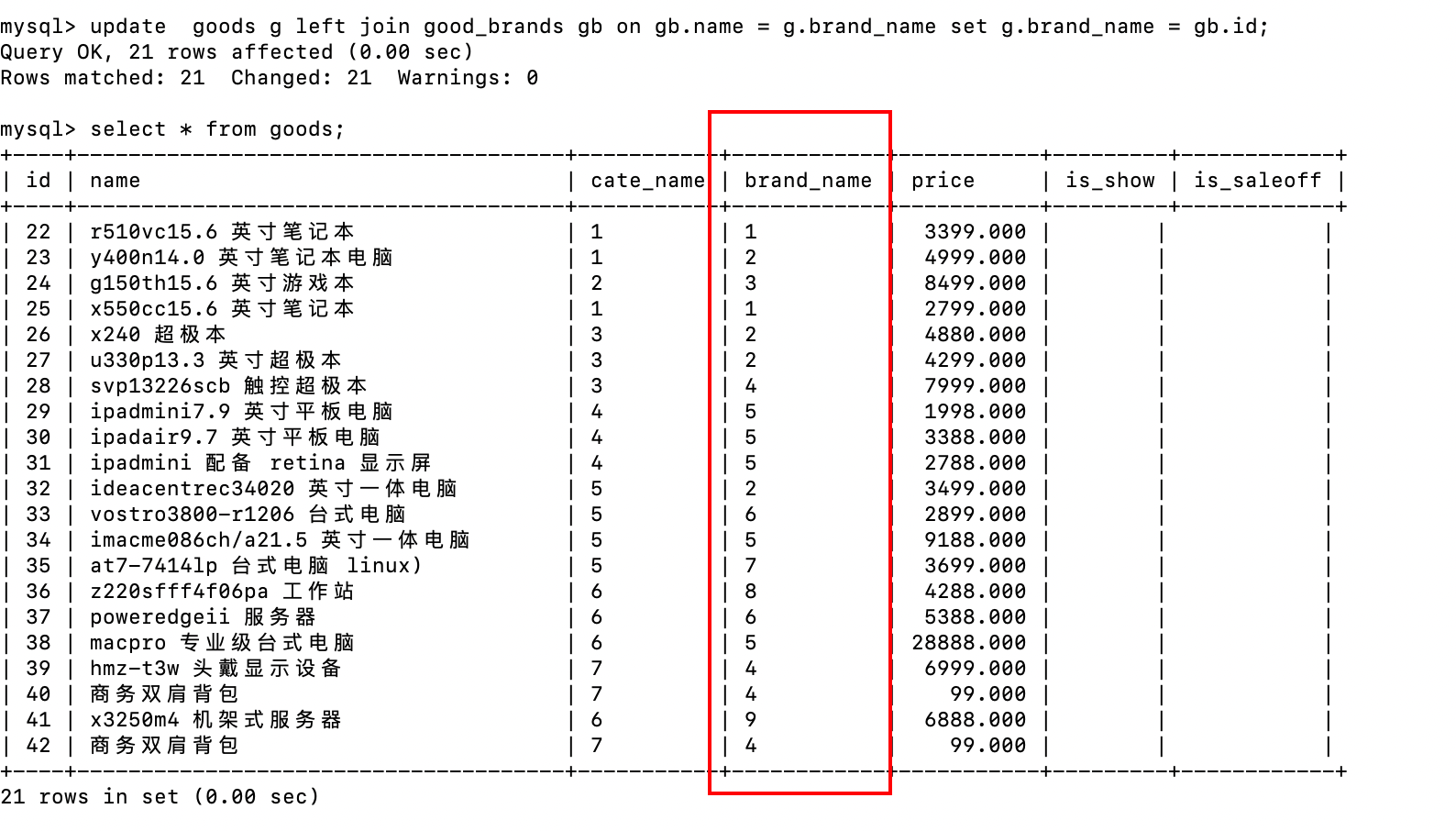
-- 将goods表中的品牌名称更改成品牌表中对应的品牌id
update goods g left join good_brands gb on gb.name = g.brand_name set g.brand_name = gb.id;
3.3查询商品的完整信息
- 查看goods商品表
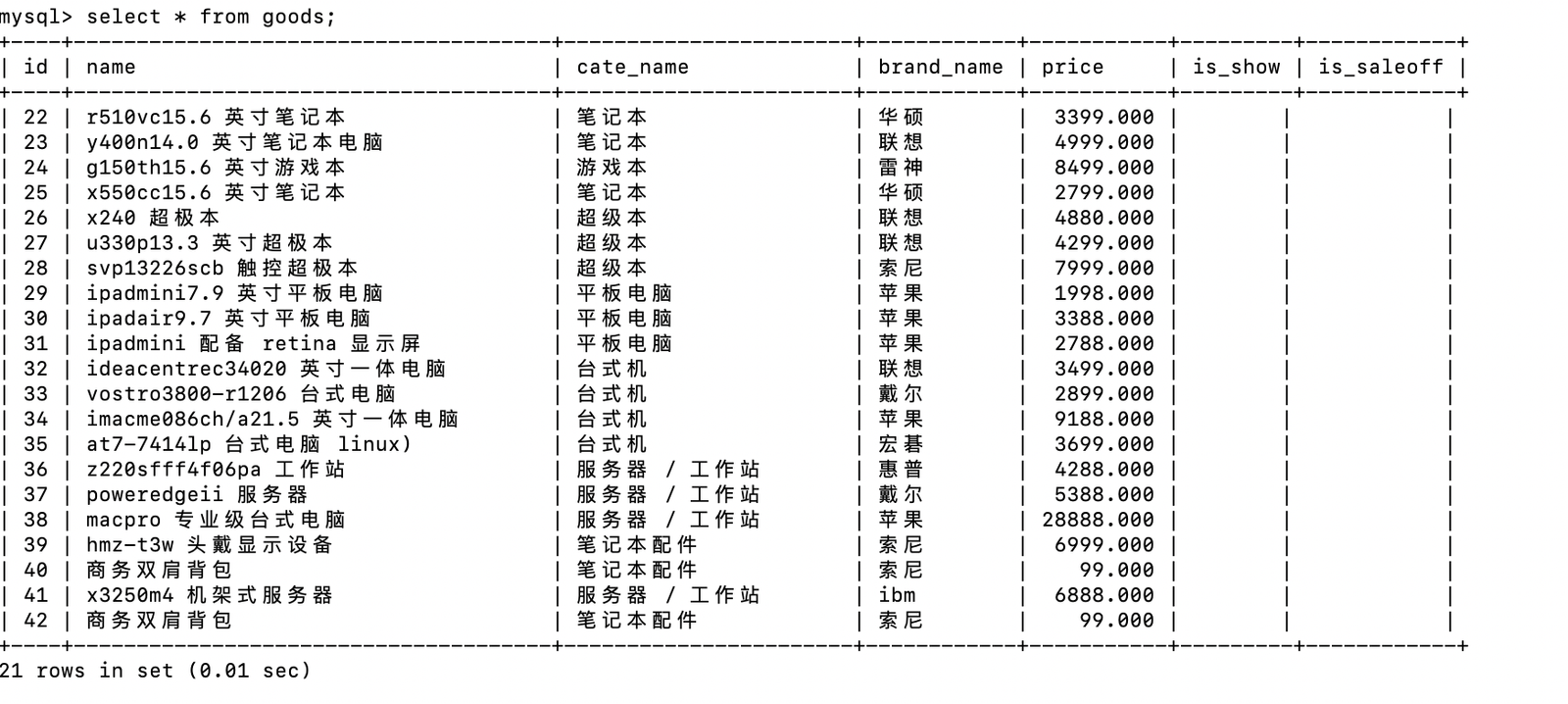
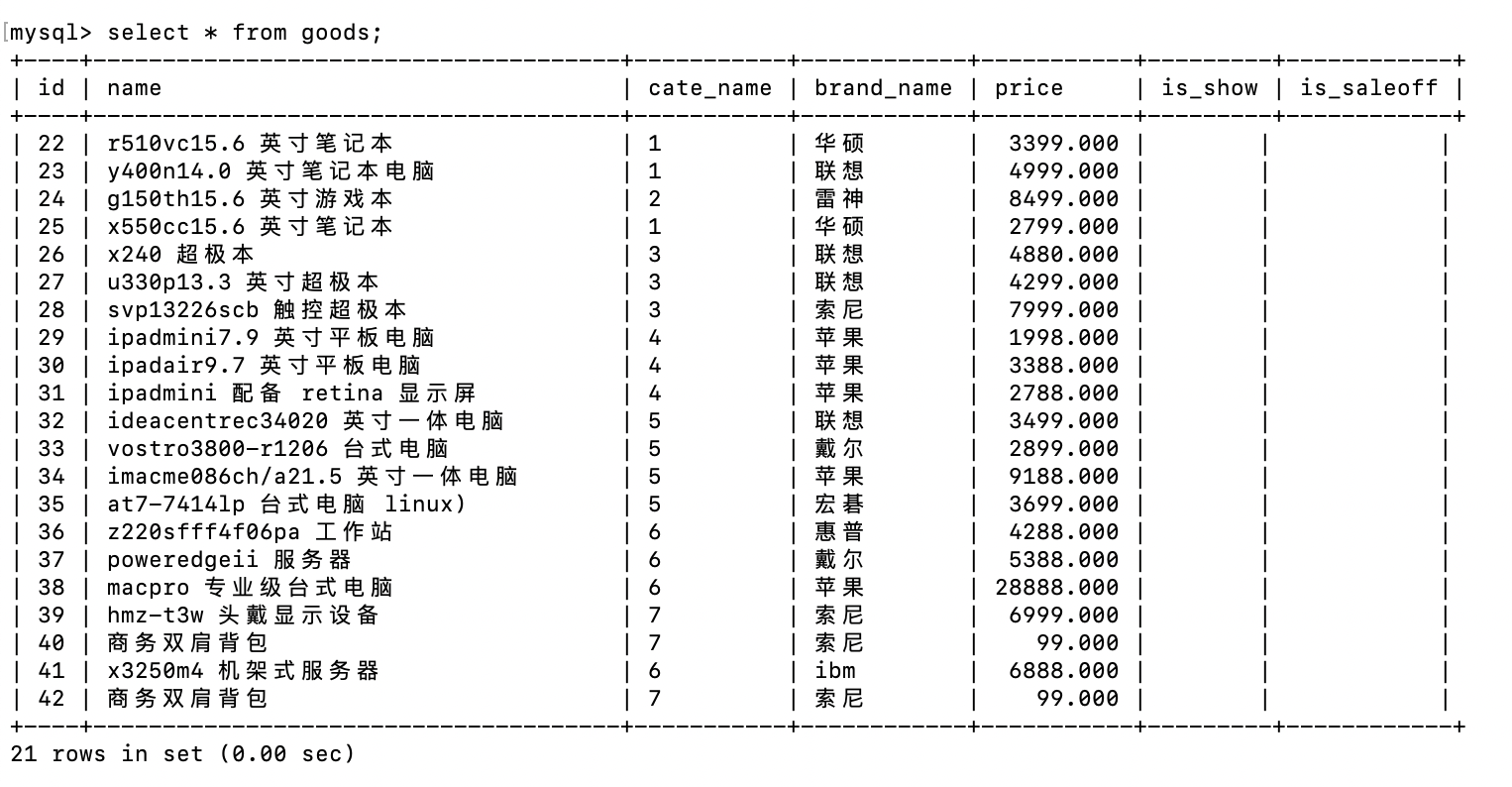
select * from goods;
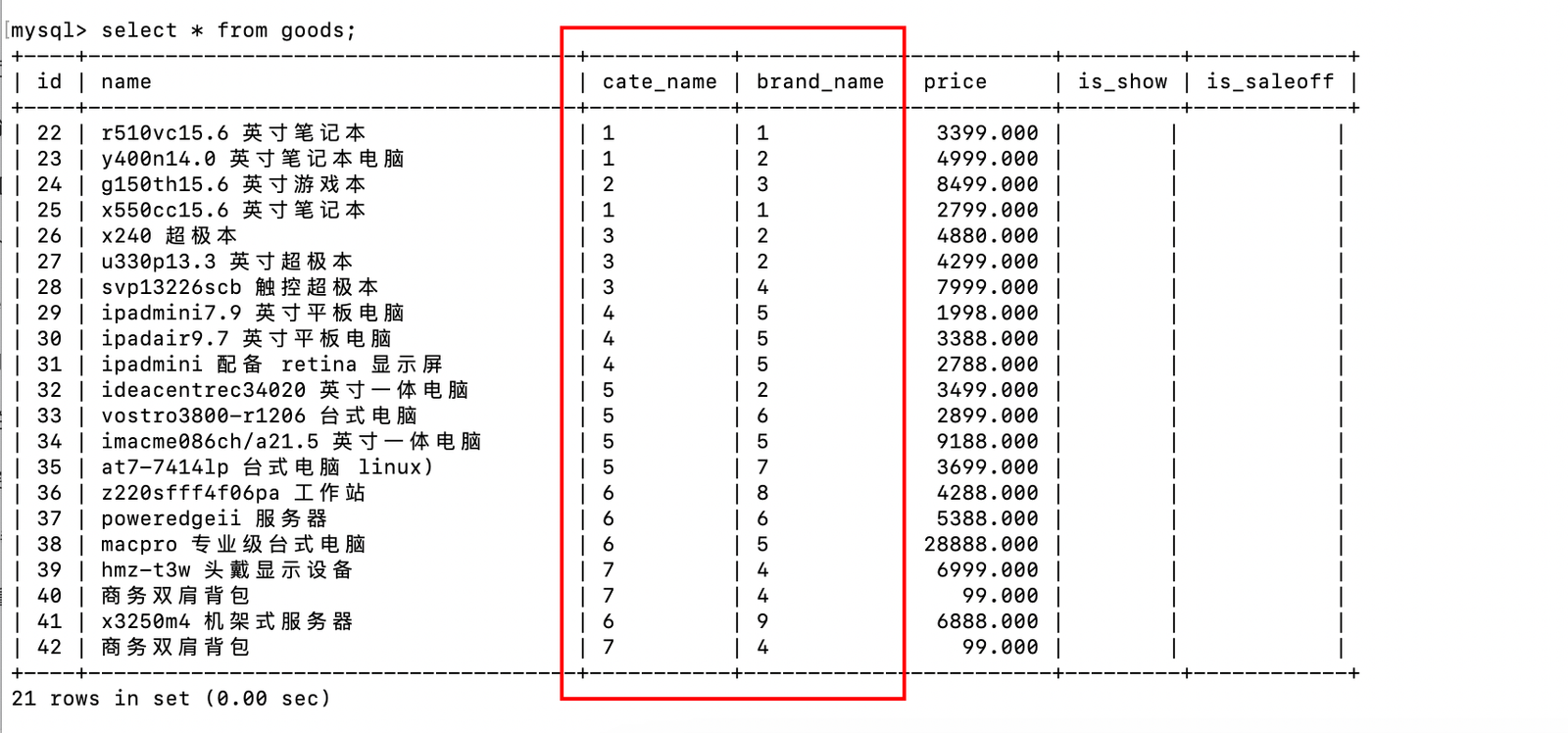
- 通过多表关联,将分散在三个表中的商品基础信息、分类信息、品牌信息聚合在一起
select g.name 商品名称,gc.name 商品类别,gb.name 品牌名称 from goods g left join good_cates gc on g.cate_name = gc.id left join good_brands gb on g.brand_name = gb.id;

4.修改goods表结构
我们已经把good表中的商品分类和品牌信息更改成了商品分类id和品牌id,接下来需要把cate_name 和brand_name字段分别改成cate_id和brand_id字段,类型都改成int类型。
-- 查看表结构
desc goods;
-- 通过alter table语句修改表结构
alter table goods change cate_name cate_id int not null,change brand_name brand_id int not null;
ALTER TABLE语句支持同时同时修改多个字段,只需在一条语句中用逗号分隔多个修改操作即可。CHANGE需要同时指定「旧字段名」和「新字段名」(即使字段名不变,也要写两次)MODIFY不需要指定新字段名,直接写「字段名 类型及约束」即可
5.PyMySQL的使用
5.1 安装PyMySQL
首先需要通过 pip 安装:
python3 -m pip install pymysql
5.2 基本使用步骤
- 连接数据库
使用 pymysql.connect() 建立连接,需要提供数据库连接信息:
import pymysql
# 连接数据库
db = pymysql.connect(
host="localhost", # 数据库主机地址(默认localhost)
user="root", # 数据库用户名
password="123456", # 密码
database="demo", # 要连接的数据库名
port=3306, # 端口号(默认3306)
charset="utf8mb4" # 字符集(支持中文需指定utf8mb4)
)
# 创建游标对象(用于执行SQL语句)
cursor = db.cursor()
- 执行SQL语句
通过游标对象的 execute() 方法执行 SQL,分两种场景:
(1)查询操作 (SELECT)
try:
#执行查询语句
#在 PyMySQL 中使用参数化查询时,占位符统一使用 %s
sql = "select id,name from students where age > %s"
cursor.execute(sql,(16))
#获取结果
result = cursor.fetchall() #获取所有记录
#result = cursor.fetchone() #获取单条记录
#result = cursor.fetchmany(3) #获取前3条记录
for row in result:
print(f"ID:{row[0]},name:{row[1]}")
except Exception as e:
print(f"查询失败:{e}")
(2)增删改操作(INSERT/UPDATE/DELETE)
这类操作需要手动提交事务(或设置自动提交):
- INSERT
try:
#示例:插入数据
sql = "insert into students (name,age) values(%s,%s)"
data = ("云9",19)
cursor.execute(sql,data)
# 提交事务(必须执行,否则修改不生效)
# cursor.rowcount 用于返回SQL语句执行后影响的行数
db.commit()
print("---------执行插入语句---------")
print("插入成功,影响行数:",cursor.rowcount)
except Exception as e:
#出错时回滚
db.rollback()
print(f"操作失败:{e}")
- UPDATE
try:
#示例:更新数据
sql = "update students set name = %s where id = %s"
data = ("十九",7)
cursor.execute(sql,data)
#提交事务
# db.commit()
print(f"---------执行更新语句:{sql}---------",data)
print("更新成功,影响行数:",cursor.rowcount)
except Exception as e:
#出错时回滚
db.rollback()
print(f"操作失败:{e}")
- DELETE
try:
#示例: 删除数据
sql = "delete from students where name = %s"
data = "十九"
cursor.execute(sql,'十九')
#提交事务
db.commit()
full_sql = cursor.mogrify(sql,data)
print(f"---------执行删除数据:{full_sql}---------")
print("更新成功,影响行数:",cursor.rowcount)
except Exception as e:
#出错时回滚
db.rollback()
print(f"操作失败:{e}")
- 关闭连接
操作完成后,需关闭游标和数据库连接:
cursor.close() # 关闭游标
db.close() # 关闭数据库连接
注意事项:
-
参数化查询: 始终使用
%s作为占位符,并在execute()第二个参数传入数据,避免 SQL 注入。 -
事务处理:默认情况下,PyMySQL 不会自动提交事务,增删改操作后需调用
db.commit()确认,出错时用db.rollback()回滚。 -
字符集: 连接时指定
charset="utf8mb4"以支持中文和特殊字符(如 emoji)。
5.3 高级用法
- 批量插入
sql = "insert into students(name,age) values(%s,%s)"
data_list = [('小张',16),('小李',17),('小王',18)]
cursor.executemany(sql,data_list)
db.commit()
- 上下文管理器(自动关闭连接)
with pymysql.connect(...) as db:
with db.cursor()as cursor:
cursor.execute("SELECT * FROM students")
print(cursor.fetchall())
# 退出with块后,游标和连接会自动关闭
6.事务详解
6.1 事务的介绍
事务(Transaction)是数据库中一组不可分割的 SQL 操作序列,这组操作要么 “全部执行成功”,要么 “全部执行失败回滚”,不存在 “部分执行” 的中间状态。
-
支持事务的引擎: InnoDB(MySQL 5.5 及以后的默认存储引擎)、NDB Cluster 等;
-
不支持事务的引擎: MyISAM(仅支持表级锁,无事务能力)、MEMORY 等。
因此,使用事务前需确保表的存储引擎为 InnoDB。
6.2 事务的四大特性(ACID)
| 特性 | 核心含义 | 示例(转账场景) |
|---|---|---|
| 原子性 | 事务中的所有操作 “要么全成功,要么全失败败”(不可分割),无中间态;若失败,事务会回滚到执行前的初始状态。 | 若 A 的余额减 100 成功,但 B 的余额加 100 失败,事务回滚,A 的余额恢复为原始值,避免数据不一致。 |
| 一致性 | 确保事务执行前后数据符合业务规则和约束条件。 | 转账前 A+B 的总余额为 1000 元,事务执行后总余额仍为 1000 元(无 “钱凭空消失或增加” 的情况)。 |
| 隔离性 | 多个并发事务之间相互隔离,一个事务的执行过程不会被其他事务干扰。也就是这个事务提交前,这个事务的修改内容对其他事务都是不可见的。 | 事务 1(A 向 B 转账)和事务 2(A 查询余额)并发时,事务 2 不会看到 “事务 1 中 A 已扣钱但 B 未加钱” 的中间状态。 |
| 持久性(Durability) | 事务一旦 "提交(COMMIT)”,其对数据的修改就是永久性的,即使后续发生服务器断电等故障,数据也不会丢失。 | 事务 1 提交后,A 的余额 - 100、B 的余额 + 100 已写入磁盘,即使此时 MySQL 崩溃,重启后数据仍保持提交后的状态。 |
- 原子性、隔离性是实现一致性的基础;
- 持久性依赖于数据库的存储机制(如 InnoDB 的 redo log 日志,确保提交后的数据不丢失)。
6.3 事务的使用
MySQL 中事务的使用主要通过 SQL 命令控制,核心包括 “事务开启、SQL 操作、事务提交 / 回滚” 三个步骤,同时需注意事务的隔离级别配置。
事务的控制命令
MySQL 默认采用 “自动提交模式(autocommit=ON)”: 即每执行一条 SQL 语句(如 INSERT/UPDATE/DELETE),就会自动作为一个独立事务提交。若需手动控制事务(多 SQL 打包),需先关闭自动提交,再通过命令管理事务。
核心命令表
| 命令 | 作用 | 说明 |
|---|---|---|
SET autocommit = OFF; |
关闭自动提交 | 仅对当前会话生效,后续 SQL 需手动提交 / 回滚;若要全局生效,需修改 MySQL 配置文件(my.cnf)中的 autocommit=0。 |
START TRANSACTION; 或 BEGIN; |
开启事务 | 替代 “关闭自动提交” 的更灵活方式: 明确标记事务的起始点,后续 SQL 均属于该事务。 |
COMMIT; |
提交事务 | 确认事务中所有 SQL 的修改,将数据永久写入数据库,事务结束。 |
ROLLBACK; |
回滚事务 | 撤销事务中所有 SQL 的修改,数据恢复到事务开启前的状态,事务结束。 |
SAVEPOINT 保存点名称; |
创建保存点 | 在事务中创建 “中间节点”,后续可通过 ROLLBACK TO 保存点名称; 回滚到该节点(而非回滚整个事务),适合复杂事务的部分回滚。 |
ROLLBACK TO 保存点名称; |
回滚到保存点 | 仅撤销 “保存点之后” 的 SQL 操作,保存点之前的操作仍属于当前事务(需后续 COMMIT 才生效)。 |
RELEASE SAVEPOINT 保存点名称; |
删除保存点 | 不再需要某个保存点时,可手动删除。 |
事务使用示例(更新场景)
以班级表为例,更新高一(1)班和高一(4)班的班主任互换

import pymysql
#连接数据库
db = pymysql.connect(
host = "localhost",
user = "root",
password = "123456",
database = "demo",
port = 3306,
charset = "utf8mb4"
)
with db:
with db.cursor() as cursor:
try:
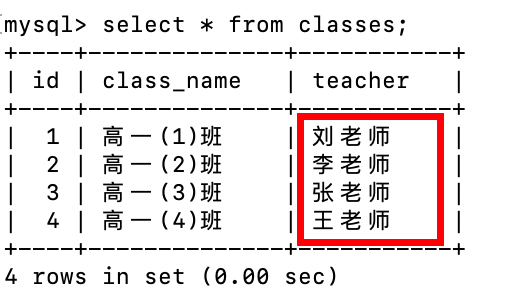
#执行事务内的SQL操作,先查询高一(1)班班主任和高一(4)班班主任
sql = "select class_name,teacher from classes"
# data = ('高一(1)班','高一(4)班')
cursor.execute(sql)
result = cursor.fetchall() #获取全部结果,元组形式
for row in result:
if row[0] == "高一(1)班":
sql = f"update classes set teacher = '{row[1]}' where class_name = '高一(4)班'"
cursor.execute(sql)
elif row[0] == "高一(4)班":
sql = f"update classes set teacher = '{row[1]}' where class_name = '高一(1)班'"
cursor.execute(sql)
db.commit()
except Exception as e:
#出错时回滚
db.rollback()
print(f"操作失败:{e}")
事务要么全部执行成功,要么全部执行失败,当出现错误时会回滚,
6.4事务的隔离级别
隔离性是 ACID 的核心,但 “完全隔离” 会导致并发性能下降(如锁等待)。MySQL 提供了四种隔离级别,允许在 “隔离性” 和 “并发性能” 之间做权衡。
四种隔离级别(从低到高)
| 隔离级别 | 核心特点 | 解决的问题 | 存在的问题 |
|---|---|---|---|
| 读未提交(Read Uncommitted) | 一个事务能读取到其他事务未提交的修改(“脏读”)。 | 无(隔离性最差) | 脏读、不可重复读、幻读 |
| 读已提交(Read Committed) | 一个事务只能读取到其他事务已提交的修改,避免脏读。 | 脏读 | 不可重复读、幻读 |
| 可重复读(Repeatable Read) | 事务开启后,多次读取同一数据的结果始终一致(即使其他事务修改并提交了该数据),避免不可重复读。 | 脏读、不可重复读 | 幻读(InnoDB 通过 “间隙锁” 实际已解决幻读) |
| 串行化(Serializable) | 最高隔离级别,强制事务串行执行(一个事务执行时,其他事务需排队等待),完全隔离。 | 脏读、不可重复读、幻读 | 并发性能极差.仅适合数据一致性要求极高且并发量低的场景(如银行对账)。 |
关键概念解释
- 脏读(Dirty Read):读取到其他事务未提交的 “临时修改”,若该事务后续回滚,读取到的数据就是 “无效的脏数据”。
- 不可重复读(Non-Repeatable Read): 同一事务内,多次读取同一行数据,结果不一致(因其他事务修改并提交了该数据)。
- 幻读(Phantom Read): 同一事务内,多次执行 “范围查询”(如
SELECT * FROM user WHERE balance > 100),结果集中的行数不一致(因其他事务插入 / 删除了符合条件的行)。
隔离级别的配置
- 查看当前隔离级别
-- MySQL 8.0+
SELECT @@transaction_isolation;
- 设置隔离级别(仅当前会话生效):
-- 格式:SET [SESSION/GLOBAL] TRANSACTION ISOLATION LEVEL 隔离级别;
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- 设置为可重复读(InnoDB默认级别)
- 默认隔离级别: InnoDB 默认使用 可重复读(Repeatable Read),这是 MySQL 对 InnoDB 的优化(通过 MVCC 多版本并发控制技术,在保证隔离性的同时兼顾性能)。
7.索引详解
7.1 索引的介绍
索引是提升查询效率的核心技术之一,相当于书籍的"目录" ,通过目录即可快速定位目标内容(数据行)。
核心作用是建立"索引键"与"数据行物理地址/主键"的映射关系,让数据库能通过索引快速定位到目标数据,避免全表扫描。
索引优缺点:
| 优点 | 缺点 |
|---|---|
| 大幅提升查询效率,减少 IO 消耗 | 增加写入操作(INSERT/UPDATE/DELETE)的耗时(需同步维护索引) |
| 辅助排序 / 分组,避免额外排序操作 | 占用额外存储空间(索引文件独立于数据文件) |
7.2 索引的使用
索引的创建
MySQL 支持通过 CREATE INDEX 或 ALTER TABLE 语句创建索引,需指定索引类型、关联字段和索引名称(自定义,需唯一)。
- 基本语法
-- 1. CREATE INDEX(推荐,语法清晰)
CREATE [索引类型] INDEX [索引名] ON [表名] ([字段1] [ASC/DESC], [字段2] ...);
-- 2. ALTER TABLE(适用于创建主键/唯一索引等特殊场景)
ALTER TABLE [表名] ADD [索引类型] INDEX [索引名] ([字段1], [字段2] ...);
- 常见索引场景示例
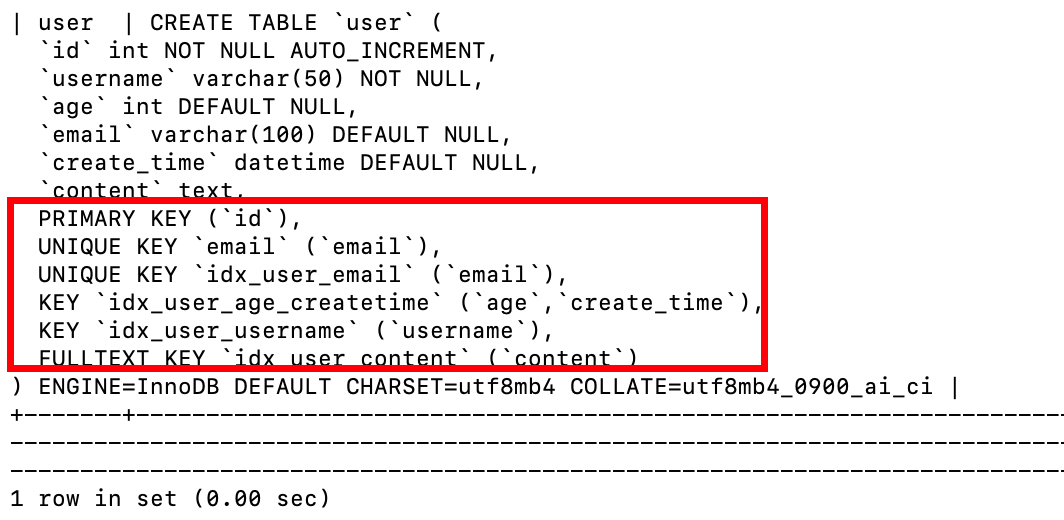
假设存在表 user,结构如下:
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键(默认自带主键索引)
username VARCHAR(50) NOT NULL,
age INT,
email VARCHAR(100) UNIQUE, -- 唯一约束(默认自带唯一索引)
create_time DATETIME
);
- 单值索引 (仅关联一个字段):
-- 为 username 字段创建单值索引,加速 username 相关查询
create index idx_user_username on user(username);
-- 方法2 使用alter建立索引
alter table user add index idx_user_username(username);
- 联合索引(关联多个字段,遵循 “最左前缀原则”)
-- 为 (age, create_time) 创建联合索引,加速“按年龄过滤 + 按创建时间排序”的查询
create index idx_user_age_createtime on user(age, create_time);
- 唯一索引(确保索引字段值唯一,避免重复数据):
-- 为 email 创建唯一索引(若表中已有重复 email,创建会失败)
create unique index idx_user_email on user(email);
- 全文索引(针对文本字段):
-- 先添加 text 字段,再创建全文索引
alter table user add column content text;
create fulltext index idx_user_content on user(content);
索引的查询
通过 SHOW CREATE TABLE或 INFORMATION_SCHEMA.STATISTICS 可以查看表的索引信息:
-- 1. `SHOW CREATE TABLE` 查看指定表的所有索引
SHOW CREATE TABLE user;
-- 2. 查看指定表的索引(详细,支持筛选)
SELECT
TABLE_NAME AS 表名,
INDEX_NAME AS 索引名,
COLUMN_NAME AS 索引字段,
INDEX_TYPE AS 索引类型
FROM INFORMATION_SCHEMA.STATISTICS
WHERE TABLE_SCHEMA = 'demo' AND TABLE_NAME = 'user';

索引的删除
当索引不再使用或影响写入性能时,需删除冗余索引:
-- 语法:DROP INDEX [索引名] ON [表名]
DROP INDEX idx_user_username ON user; -- 删除 username 字段的单值索引
7.3 索引使用的关键原则
索引并非"越多越好",需遵循以下原则避免无效索引或性能反降:
(1)最左前缀原则(联合索引核心)
联合索引(如 (a, b, c))的生效顺序是 "从左到右",仅当查询条件包含最左侧字段时,索引才会生效。例如:
-
生效场景:
WHERE a=1、WHERE a=1 AND b=2、WHERE a=1 AND b=2 AND c=3 -
失效场景:
WHERE b=2(无 a)、WHERE b=2 AND c=3(无 a)、WHERE a=1 AND c=3(跳过 b,仅 a 生效)
(2)避免索引失效的常见场景
- 函数 / 运算操作索引字段: 如
WHERE SUBSTR(username, 1, 3)= '张'(索引失效,需改为WHERE username LIKE '张%')。 - 字段类型不匹配: 如
username是VARCHAR类型,查询时用WHERE username = 123(隐式转换,索引失效,需改为WHERE username = '123')。 - 使用
NOT IN、!=、<>: 这类操作会导致索引失效,优先用IN或范围查询替代。 LIKE以%开头: 如WHERE username LIKE '%三'(索引失效,LIKE '三%'或LIKE '三%五'生效)。- 联合索引中右侧字段单独查询: 违反 “最左前缀原则”,索引失效。
(3)适合创建索引的场景
- 频繁出现在
WHERE条件、JOIN关联(如ON a.id = b.a_id)中的字段。 - 用于
ORDER BY、GROUP BY的字段(优先创建联合索引,包含排序 / 分组字段)。 - 区分度高的字段(如
id、username,区分度低的字段如gender(男 / 女)不适合建索引)。
(4)不适合创建索引的场景
- 数据量极小的表(如仅几十行的配置表,全表扫描比索引查询更快)
- 频繁更新/删除的字段(索引需同步维护, 写入成本高)
- 查询中不使用的字段(冗余索引,浪费空间)
7.4 案例- 验证索引查询性能
准备环境
-
数据库: MySQL 8.0(InnoDB 引擎)
-
测试表 testidx (模拟万级数据)
-
表结构:
mysql> create table testidx(id int primary key auto_increment,username varchar(50) NOT NULL);
- 插入数据: 通过pymysql插入一万条测试数据
import pymysql
#连接数据库
db = pymysql.connect(
host = "localhost",
user = "root",
password = "123456",
database = "demo",
port = 3306,
charset = "utf8mb4"
)
with db:
with db.cursor() as cursor:
try:
for i in range(10000):
sql = "insert into testidx(username) values(%s)"
cursor.execute(sql,"test"+str(i))
except Exception as e:
db.rollback()
print(f"操作失败:{e}")
db.commit()
print("数据插入成功")
无索引查询测试
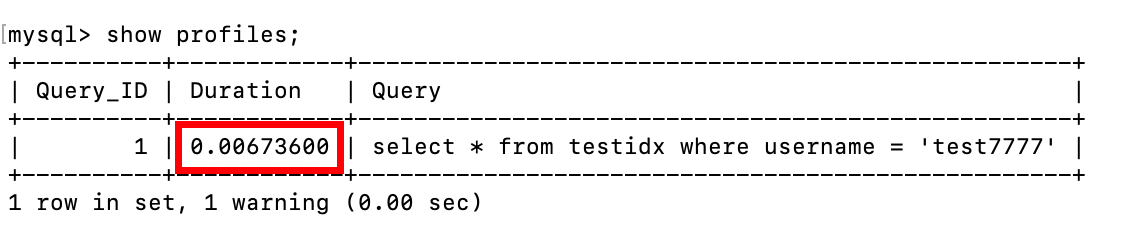
查询 “用户名为 test7777的用户”,此时 username 字段无索引,MySQL 会执行全表扫描:
-- 开启查询时间统计
SET profiling = 1;
-- 无索引查询:用户名为 test7777的用户
select * from testidx where username = 'test7777';
-- 查看查询耗时
SHOW PROFILES;
有索引查询测试
为 username 字段创建单值索引,再次执行相同查询:
-- 为 username 字段创建索引
create index testidx_username on testidx(username);
-- 有索引查询:用户名为 test7777的用户
select * from testidx where username = "test7777";
-- 查看查询耗时
SHOW PROFILES;

8. MySQL 备份与恢复
8.1 MySQL备份: mysqldump
原理: 将数据库 / 表的结构和数据导出为 SQL 脚本(文本文件),恢复时执行脚本即可重建数据。
- 备份所有数据库(含系统库,如
mysql、information_schema):
# 语法:mysqldump -u用户名 -p密码 --all-databases > 备份文件.sql
mysqldump -uroot -ptoor --all-databases > all_db_backup.sql
- 备份指定单个数据库(如备份
demo库):
mysqldump -uroot -ptoor --databases demo > demo_backup.sql
- 备份指定数据库的多个表(如备份
demo库的students和classes表):
mysqldump -uroot -ptoor demo students classes > demo_students_classes_backup.sql
8.2 MySQL恢复操作
- 恢复所有数据库
mysql -uroot -p123456 < all_db_backup.sql
- 恢复单个数据库
先把demo数据库删掉
drop database demo;
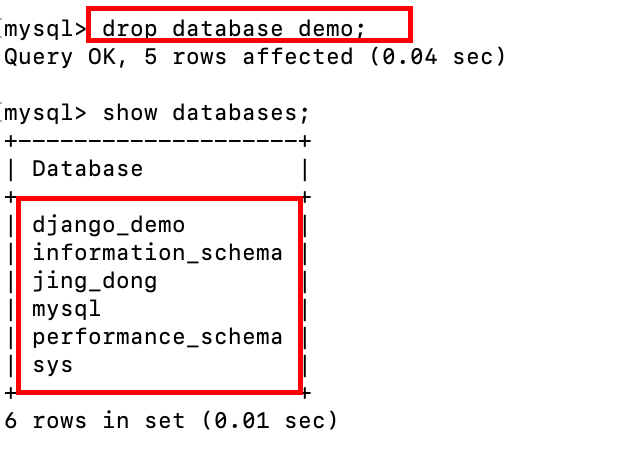
使用语句恢复demo数据库
# 语法:mysql -u用户名 -p密码 数据库名 < 备份文件.sql
mysql -uroot -ptoor < demo_backup.sql
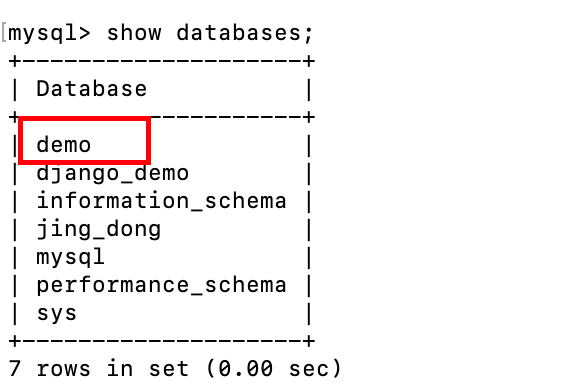
命令恢复完
show databases;查看可以看到我们的demo数据库恢复成功
9. MySQL存储过程详解
存储过程是预编译并存储在MySQL数据库中的一组SQL语句集合,可通过名称直接调用,提高代码的复用性。
9.1 存储过程的基本概念
核心特点:
- 预编译: 创建时编译,调用时直接执行
- 封装性: 将多步SQL逻辑封装为一个单元
- 安全性: 允许用户调用不暴露底层SQL
- 减少网络传输: 客户端只需发送调用命令,无需传输整条SQL
适合场景:
- 批量数据操作
- 需要重复执行的SQL序列
9.2 存储过程的基本语法
1.创建存储过程
DELIMITER // -- 临时修改分隔符(避免 SQL 中的 ; 提前结束存储过程)
CREATE PROCEDURE 存储过程名(参数列表)
BEGIN
-- 存储过程逻辑(SQL 语句集合)
END //
DELIMITER ; -- 恢复默认分隔符
关键说明:
DELIMITER: 默认分隔符为;,但存储过程中可能包含多个;,需临时修改为其他符号(如//或$$),创建后再恢复参数列表: 格式为[IN/OUT/INOUT] 参数名 数据类型,如IN user_id INT
2.参数类型
MySQL 存储过程支持 3 种参数类型:
| 类型 | 作用 | 示例 |
|---|---|---|
IN |
输入参数(调用时传入,存储过程内可读) | IN username VARCHAR(50) |
OUT |
输出参数(存储过程内赋值,调用后可获取) | OUT total_count INT |
INOUT |
输入输出参数(既传入又传出) | INOUT page_num INT |
3.变量与赋值
- 声明变量: 在
BEGIN后用DECLARE声明,需指定数据类型
DECLARE 变量名 数据类型 [DEFAULT 默认值];
-- 示例
DECLARE user_count INT DEFAULT 0;
DECLARE avg_age DECIMAL(5,2);
-
赋值方式:
- 用
SET赋值:SET user_count = 10; - 用
SELECT ... INTO从查询结果赋值:
SELECT COUNT(*) INTO user_count FROM users WHERE status = 1; - 用
9.3 存储过程实例
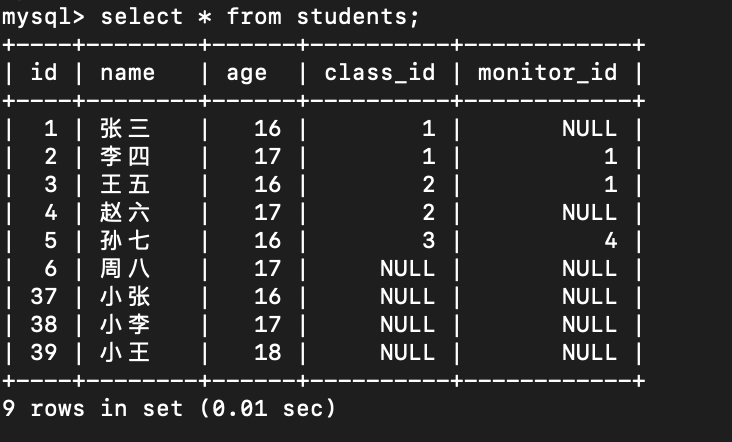
目前students表数据如下,完成实例
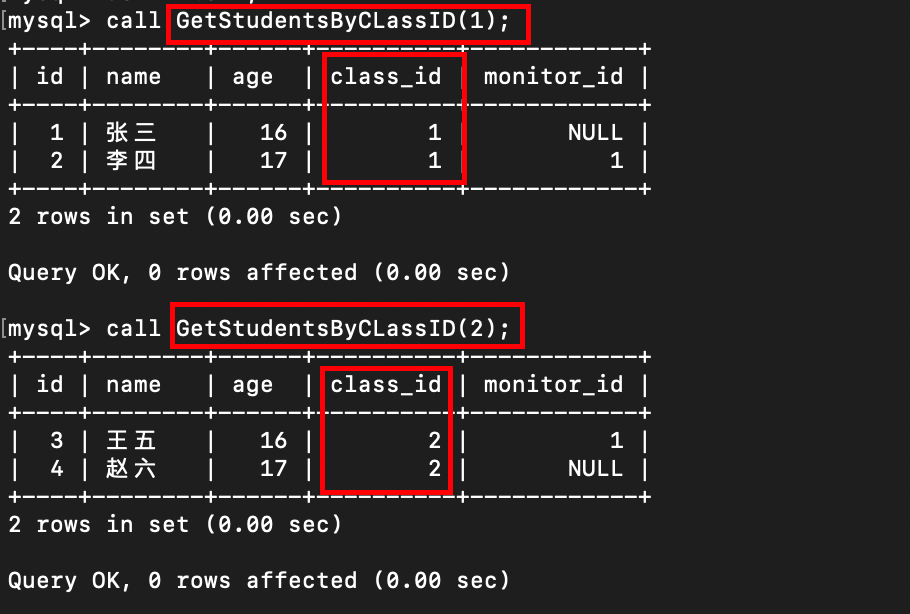
- 实例 1: 查询指定班级的学生信息
delimiter //
create procedure GetStudentsByClassID(IN classID INT)
begin
select * from students where class_id = classID;
end //
delimiter ;
-- 调用存储过程
call GetStudentsByCLassID(1);
call GetStudentsByCLassID(2);
- 实例 2: 统计指定班级的学生数量(带 OUT 参数)
delimiter //
create procedure CountStudentsByClassId(IN classId INT,OUT studentCount INT)
begin
select count(*) into studentCount from students where class_id = classId;
end //
delimiter ;
-- 调用存储过程,统计班级 ID 为 2 的学生数量
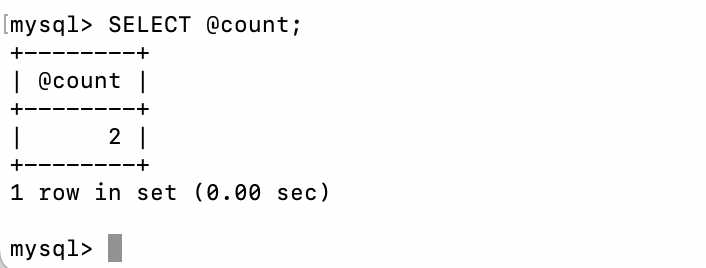
-- @符号用来表示用户变量,是一种会话级别变量,作用域仅限于当前数据库连接
-- @count作为输出参数使用,用于接收存储过程的计算结果
set @count = 0;
call CountStudentsByClassId(2,@count);
SELECT @count;
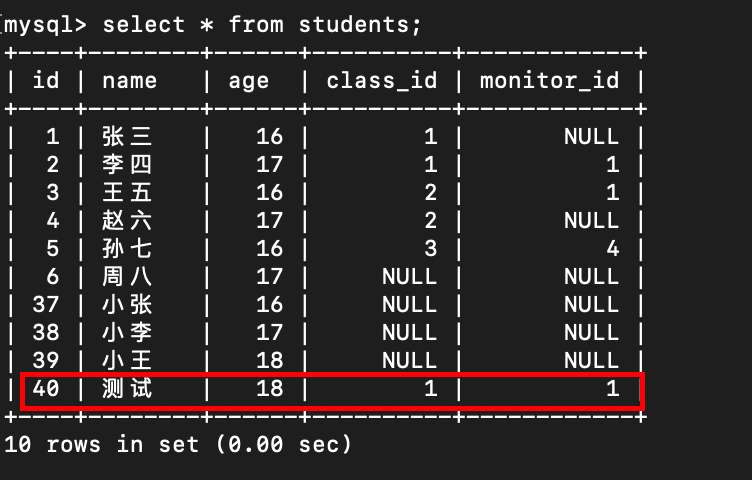
- 实例 3: 插入学生数据
delimiter //
create procedure InsertStudentInfo(
IN name VARCHAR(20),
IN age INT,
IN class_id int,
IN monitor_id int)
begin
insert into students values(0,name,age,class_id,monitor_id);
end //
delimiter ;
-- 测试插入数据
call InsertStudentInfo('测试',18,1,1);
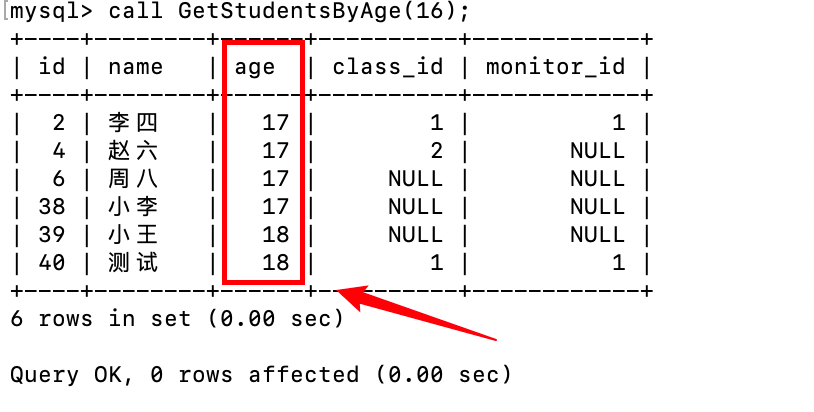
- 实例 4: 查询年龄大于指定值的学生(带条件判断)
delimiter //
create procedure GetStudentsByAge(IN ageLimit INT)
begin
if ageLimit <= 0 then
select '年龄限制不能小于等于0' as 提示;
else
select * from students where age > ageLimit;
end if;
end //
delimiter ;
-- 调用存储过程,查询年龄大于 16 的学生
CALL GetStudentsByAge(16);
9.4 存储过程的管理
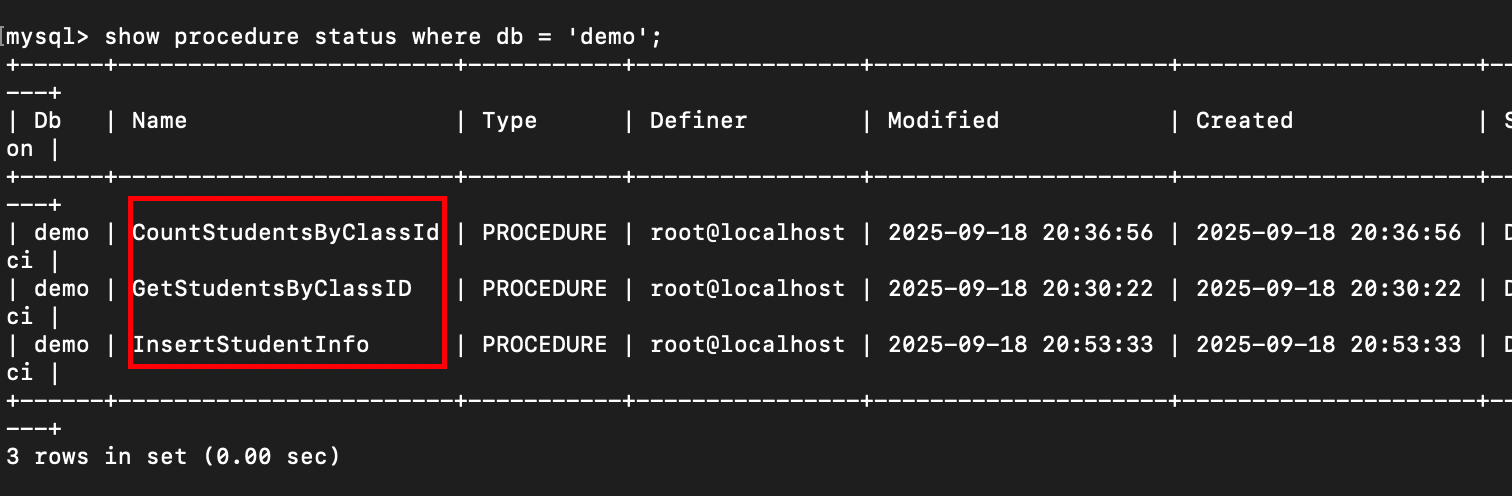
1.查看存储过程
-- 查看所有存储过程基本信息
SHOW PROCEDURE STATUS;
-- 查看指定数据库的存储过程(如 demo 库)
SHOW PROCEDURE STATUS WHERE db = 'demo';
-- 查看存储过程的创建语句(如 CountStudentsByClassId)
SHOW CREATE PROCEDURE CountStudentsByClassId;
2.删除存储过程
DROP PROCEDURE IF EXISTS 存储过程名;
-- 示例:删除 CountStudentsByClassId
drop procedure if exists CountStudentsByClassId;
