
1. BeautifulSoup4库介绍
和lxml一样,Beautiful Soup也是一个HTML/XML的解析器,主要功能也是如何解析和提取HTML/XML数据。
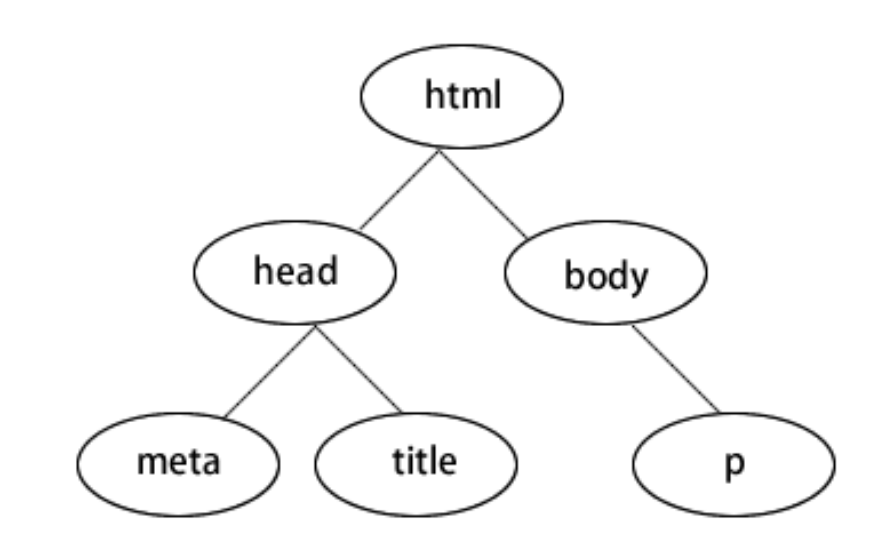
lxml只会局部遍历,Beautiful Soup是基于HTML DOM(Document Object Model)的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
DOM树
安装方法:使用pip安装
pip install beautifulsoup4
BeautifulSoup4解析引擎
我们使用requests库发送请求获取html,获得的是html字符串,只有正则表达式(re)才可以直接对html字符串进行解析(最快的方式),而对于html字符串我们无法使用xpath语法和bs4语法进行直接提取,需要通过lxml或者bs4对html字符串进行解析,解析为html页面才能进行数据提取。
在xpath中我们使用lxml进行解析,但是在bs4中,我们有很多的解析器对网页进行解析。
| 解析器 | 优势 | 安装方式 |
|---|---|---|
| html.parser | Python 内置,无需额外安装 | 内置 |
| lxml | 解析速度快,支持 HTML 和 XML | pip install lxml |
| html5lib | 处理不规范 HTML 更优,模拟浏览器解析 | pip install html5lib |
2. BeautifulSoup4数据获取
使用bs4库对以下这个index.html进行数据提取
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>招聘信息页面</title>
<style>
.company {
border: 1px solid #ccc;
padding: 10px;
margin-bottom: 15px;
border-radius: 5px;
}
.job {
background-color: #f9f9f9;
padding: 8px;
margin: 5px 0;
border-left: 3px solid #007bff;
}
.high-salary {
color: red;
font-weight: bold;
}
</style>
</head>
<body>
<div class="page-header">
<h1>互联网行业招聘信息汇总</h1>
<p>包含多家知名企业的各类岗位招聘</p>
</div>
<div class="company-list">
<div class="company" id="company-alibaba">
<h2>阿里巴巴集团</h2>
<div class="job" data-id="ali-1">
<h3>Java 高级开发工程师</h3>
<p>薪资:<span class="salary">25k-40k</span>/月</p>
<p>要求:本科及以上学历,5年以上 Java 开发经验,熟悉分布式系统</p>
<p>部门:阿里云事业部</p>
</div>
<div class="job" data-id="ali-2">
<h3>前端技术专家</h3>
<p>薪资:<span class="salary high-salary">30k-50k</span>/月</p>
<p>要求:硕士及以上学历,精通 Vue、React 等框架,有大型项目架构经验</p>
<p>部门:淘宝技术部</p>
</div>
</div>
<div class="company" id="company-tencent">
<h2>腾讯公司</h2>
<div class="job" data-id="tencent-1">
<h3>后端开发工程师</h3>
<p>薪资:<span class="salary">20k-35k</span>/月</p>
<p>要求:本科及以上学历,熟悉 Go 语言,有微服务开发经验优先</p>
<p>部门:微信事业群</p>
</div>
<div class="job" data-id="tencent-2">
<h3>测试开发工程师</h3>
<p>薪资:<span class="salary">18k-30k</span>/月</p>
<p>要求:本科及以上学历,熟悉自动化测试框架,有性能测试经验</p>
<p>部门:腾讯云测试部</p>
</div>
<div class="job" data-id="tencent-3">
<h3>产品经理</h3>
<p>薪资:<span class="salary">22k-38k</span>/月</p>
<p>要求:本科及以上学历,有社交类产品经验,逻辑思维清晰</p>
<p>部门:QQ 产品部</p>
</div>
</div>
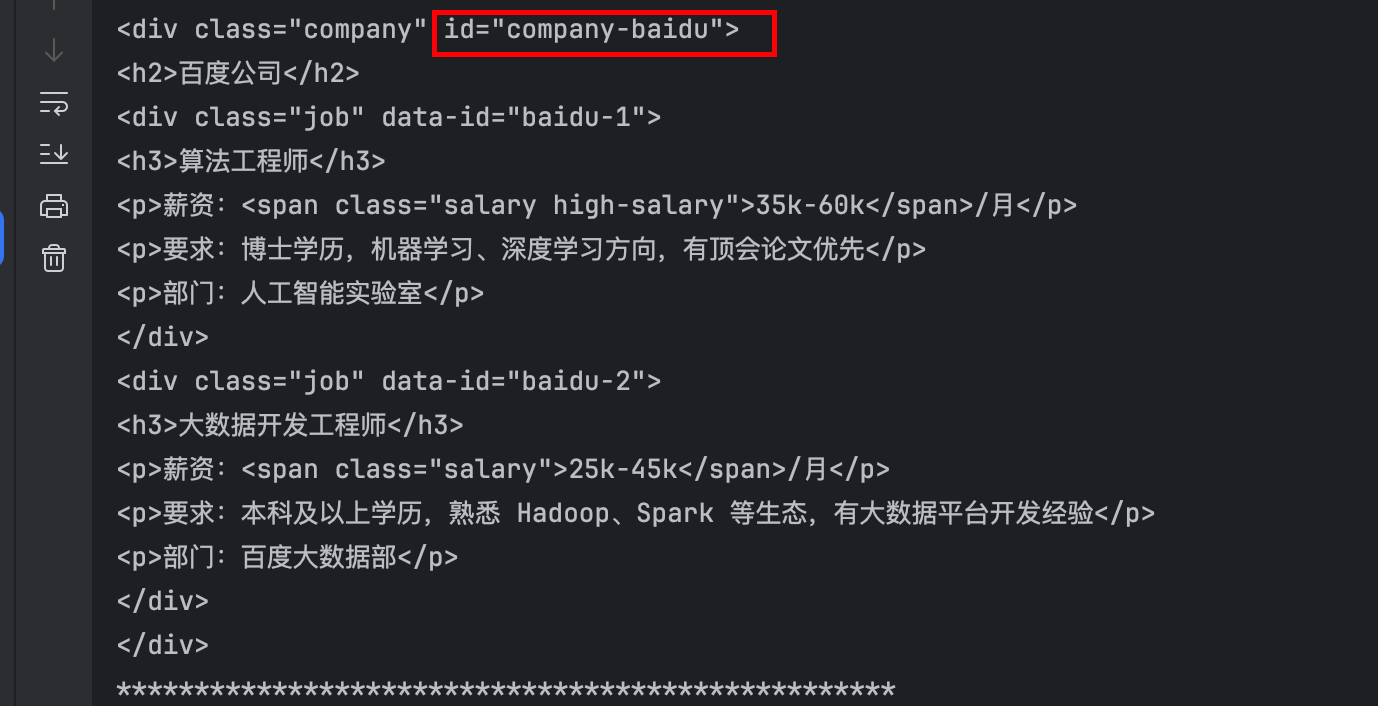
<div class="company" id="company-baidu">
<h2>百度公司</h2>
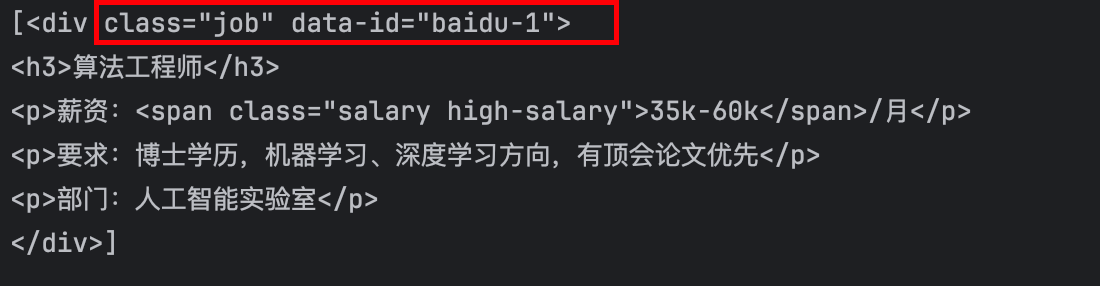
<div class="job" data-id="baidu-1">
<h3>算法工程师</h3>
<p>薪资:<span class="salary high-salary">35k-60k</span>/月</p>
<p>要求:博士学历,机器学习、深度学习方向,有顶会论文优先</p>
<p>部门:人工智能实验室</p>
</div>
<div class="job" data-id="baidu-2">
<h3>大数据开发工程师</h3>
<p>薪资:<span class="salary">25k-45k</span>/月</p>
<p>要求:本科及以上学历,熟悉 Hadoop、Spark 等生态,有大数据平台开发经验</p>
<p>部门:百度大数据部</p>
</div>
</div>
</div>
<div class="footer">
<p>招聘信息仅供参考,具体以企业官方发布为准</p>
</div>
</body>
</html>

1.导入库
from bs4 import BeautifulSoup
2.创建 BeautifulSoup 对象(解析文档)
with open("index.html","r",encoding='utf-8') as f:
soup = BeautifulSoup(f, "lxml")
- (1)获取所有的div标签
divs = soup.find_all("div")
print(divs)
- (2)获取指定的div标签(从第二个到最后一个)
divs = soup.find_all('div')[1:]
print(div)
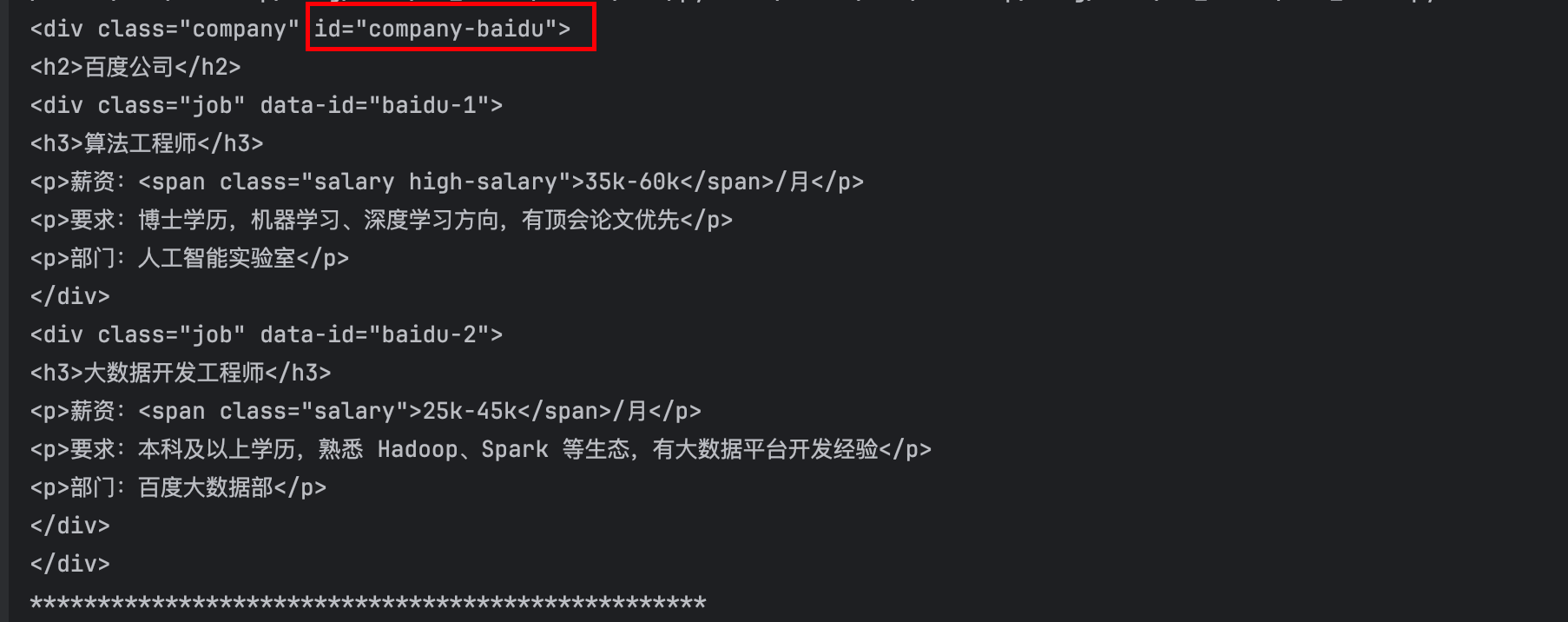
- (3)获取拥有指定属性的标签写法1(“id='company-baidu'的div标签”):用逗号分隔属性值
divs = soup.find_all('div',id='company-baidu')
for div in divs:
print(div)
print("*"*50)
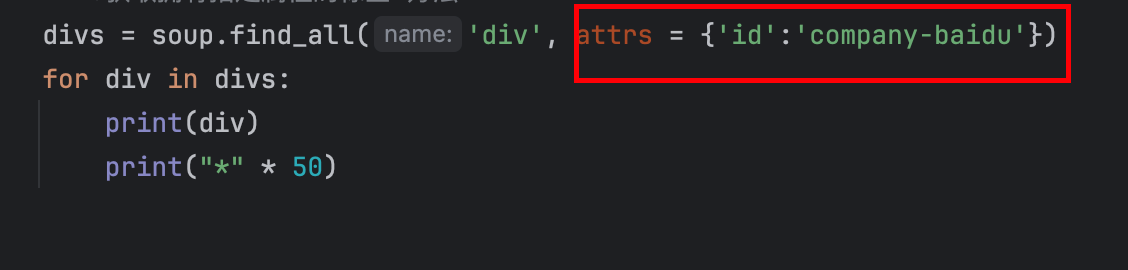
- 获取拥有指定属性的标签写法2(“id='company-baidu'的div标签”):设置attrs参数,将属性名称和属性值输入为字典中的键值对,
- (4)获取拥有多个属性的标签
# class是Python的关键字,使用方法1的话不能直接作为参数名,需要用class_ 代替
# 对于带有连字符的属性(如 data-id),不能直接作为关键字参数传递,需要用字典形式
divs = soup.find_all('div',attrs = {'class':'job','data-id':'baidu-1'})
print(divs)
-
(5)获取拥有多个属性的标签(span标签的class属性值)
- 通过下标的方式
spanlist = soup.find_all("span") for span in spanlist: class_value = span['class'] print(class_value)- 通过attrs属性获取
spanlist = soup.find_all("span") for span in spanlist: class_value = span.attrs["class"] print(class_value) -
(6)获取所有职位的信息
from bs4 import BeautifulSoup
def extract_job_info(job_title):
try:
title = job_title.find('h3').string or "未知岗位"
salary = job_title.find('span',class_='salary').string or "薪资未公开"
p_tags = job_title.find_all('p')
requirement = p_tags[1].string.split(":")[1] if len(p_tags)>=2 else "要求未公开"
department = p_tags[2].string.split(":")[1] if len(p_tags)>=3 else "部门未公开"
return {
"title": title,
"salary": salary,
"requirement": requirement,
"department": department
}
except(AttributeError,IndexError):
print(f"岗位解析错误:{e}")
return None
with open("index.html","r",encoding='utf-8') as f:
soup = BeautifulSoup(f, "lxml")
divs = soup.find_all("div",class_ = 'company')
for div in divs:
#获取公司名称
company_name = div.find('h2').string
company_name = company_name.string if company_name else "未知公司"
print(f"公司名称:{company_name}")
#获取当前公司所有岗位
job_titles = div.find_all('div',class_='job')
#遍历所有岗位
for job in job_titles:
job_info = extract_job_info(job)
if job_info:
print(f"岗位: {job_info['title']}")
print(f"薪资: {job_info['salary']}")
print(f"要求: {job_info['requirement']}")
print(f"部门: {job_info['department']}\n")
print("*"*50)
3. bs4爬虫实战
爬虫实战步骤:
1.导入模块
2.定义URL和请求头参数
3.发送html请求,获取html字符串
4.实例化BeautifulSoup对象
5.获取数据
6.存储数据
3.1 BeautifulSoup4实战练手——新浪微博
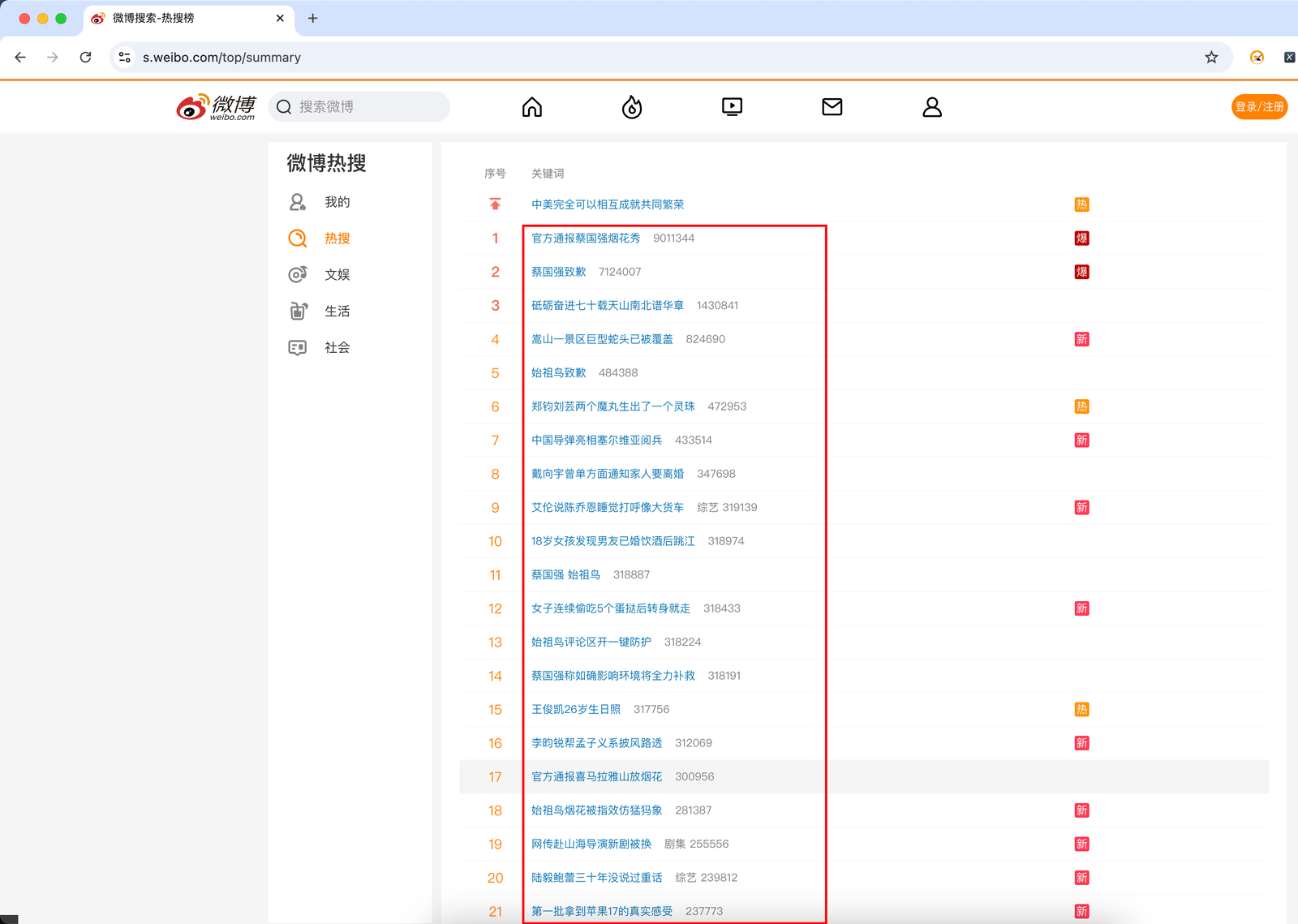
- 任务: 爬取热度榜的内容和热度值
- hint: 微博有反爬机制,可以复制信息去https://curlconverter.com/python/ 获取请求头和cookies信息
代码示例:
def get_weibo_top():
#定义URL和请求头
url = "https://s.weibo.com/top/summary"
cookies = {
'SUB': '_2AkMfNI0Df8NxqwFRmvkdzGviZY9xzwDEieKpaHzYJRMxHRl-yT9kqmkJtRB6NLSj7MvpaHOQcuWqXYtKn5BN9uhI3rp8',
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9WF0kEihP.YcLRquXMaVBn8b',
'SINAGLOBAL': '4129228658367.541.1758171541219',
'_s_tentry': '-',
'Apache': '5258822436993.217.1758423981101',
'ULV': '1758423981102:2:2:1:5258822436993.217.1758423981101:1758171541220',
}
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'priority': 'u=0, i',
'sec-ch-ua': '"Chromium";v="140", "Not=A?Brand";v="24", "Google Chrome";v="140"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36',
# 'cookie': 'SUB=_2AkMfNI0Df8NxqwFRmvkdzGviZY9xzwDEieKpaHzYJRMxHRl-yT9kqmkJtRB6NLSj7MvpaHOQcuWqXYtKn5BN9uhI3rp8; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WF0kEihP.YcLRquXMaVBn8b; SINAGLOBAL=4129228658367.541.1758171541219; _s_tentry=-; Apache=5258822436993.217.1758423981101; ULV=1758423981102:2:2:1:5258822436993.217.1758423981101:1758171541220',
}
#发送请求,获取html字符串并使用解析器解析
res = requests.get(url, headers=headers,cookies=cookies)
res.encoding = "utf-8"
html = BeautifulSoup(res.text,'lxml')
#使用bs4库方法获取目标数据
infos = html.find('div',class_="data",id="pl_top_realtimehot").find('tbody').find_all('tr')[1:]
i = 0
for info in infos:
try:
i += 1
# print(info)
print("*"*60)
title = info.find('a').text
hot = info.find('span').text
status = info.find('i').text if info.find('i') else None
print(f"{title}\t热度:{hot}\t状态:{status}")
except Exception as e:
print(f"错误信息{e}")
continue
print(f"总共输出{i}条热搜")
if __name__ == "__main__":
get_weibo_top()

3.2 BeautifulSoup4实战练手——汽车之家新闻
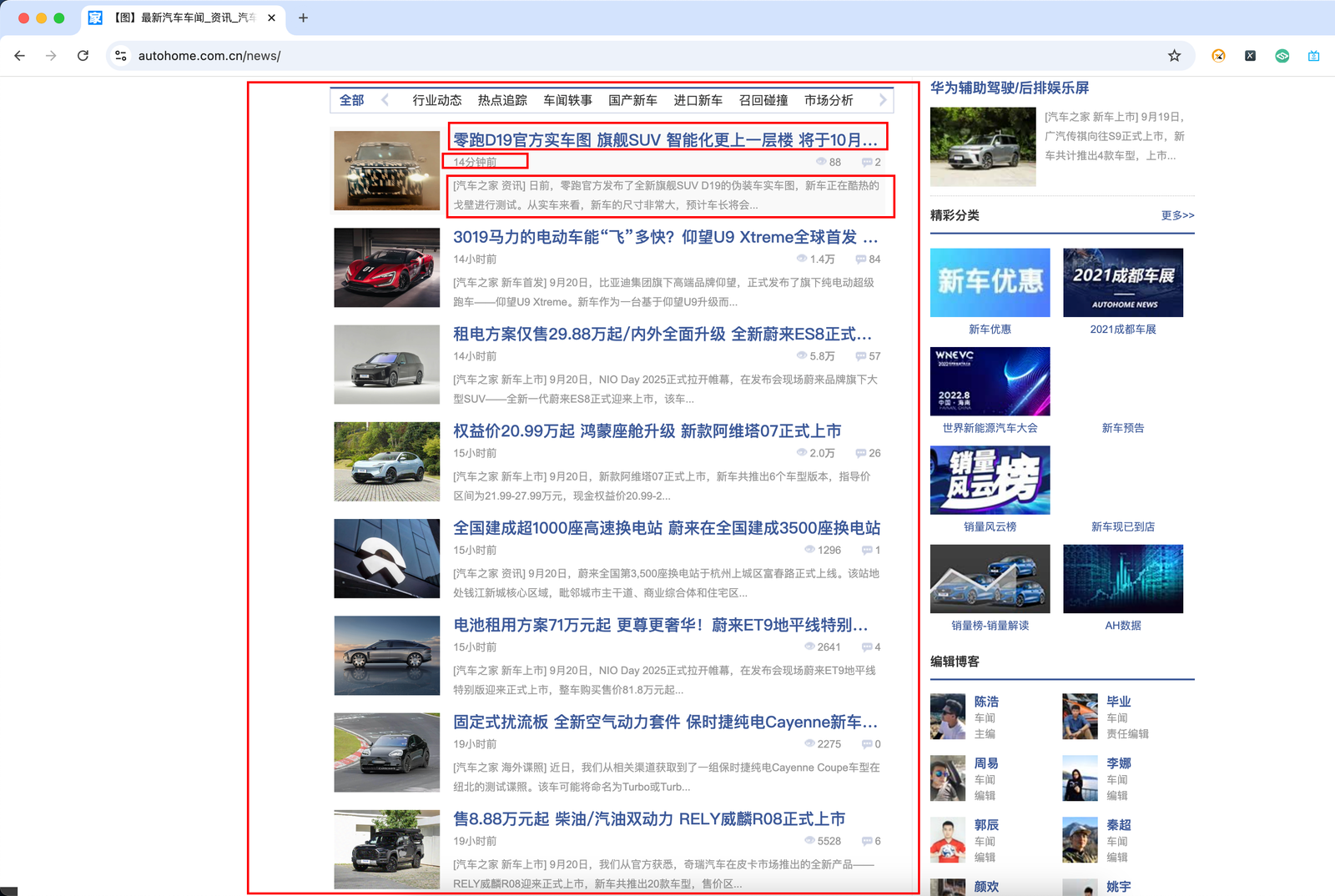
任务: 爬取汽车之家指定页数的新闻页面
爬取的数据: 新闻标题、新闻链接、发表时间、新闻概要
代码示例:
def get_car_news(num):
#1.定义URL的列表,和请求参数headers
urls = []
for i in range(1,num+1):
url = f"https://www.autohome.com.cn/news/{i}/#liststart"
urls.append(url)
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
news_list = []
#2.遍历URL 发送请求
for url in urls:
res = requests.get(url,headers=headers)
res.encoding = "gb2312"
#解析HTML字符串,获取想要数据
html = BeautifulSoup(res.text,'lxml')
#分析页面,新闻数据在四个ul标签下,获取全部ul标签然后遍历,并存储数据
uls = html.find_all('ul',class_="article")
for ul in uls:
titles = ul.find_all('h3')
hrefs = ul.find_all('a',href=True)
times = ul.find_all('span',class_="fn-left")
descriptions = ul.find_all('p')
for(title,href,time,description) in zip(titles,hrefs,times,descriptions):
title = title.text
href = href.get("href")[2:]
time = time.text
description = description.text
news = {
"标题":{title},
"链接":{href},
"发布时间":{time},
"描述":{description},
}
news_list.append(news)
#3.打印数据
for news in news_list:
print(news)
print("*"*60)
if __name__ == "__main__":
#获取前两页的新闻
get_car_news(2)
